

CodexをChatGPTみたいに使えるのか? 実験前に整えたい準備と運用ルール

CodexをChatGPTのように使えるのか。
結論から言えば、完全に同じ感覚で置き換えるのは難しいものの、準備と設計しだいで、かなり実用的なかたちまで拡張できます。

実のところ、この記事もすべてCodex上で作成しています。
つまり、CodexをChatGPTのように使うための準備として必要なのは、会話の雰囲気だけを似せることではありません。
もともとの役割がコーディング支援にあることを踏まえたうえで、出力形式、指示の与え方、スキル設計、プロジェクト単位の前提管理まで含めて整えることが重要です。
最近の高性能モデルは、コードだけでなく、説明、整理、下書き、比較検討といった通常生成にもかなり対応しやすくなっています。
ただし、それはCodexとChatGPTの違いが消えたということではなく、作業支援の幅が広がったと見るほうが実態に近いでしょう。
この前提を押さえておくと、期待しすぎて外すことも、防御的になりすぎて可能性を見逃すことも減ります。
まずは、Codexをどのような前提で使うべきかを整理していきます。
contents
CodexをChatGPTみたいに使う前に押さえるべき大前提

最初に整理しておきたいのは、CodexはChatGPTの代替として捉えるより、開発作業と強く結びついた対話型アシスタントとして見たほうが実態に近い、という点です。
ここを曖昧にしたまま使い始めると、「会話できるなら何でも同じようにこなせるはずだ」という期待が先に立ち、実際の挙動との差がそのまま不満になりやすくなります。
逆に、起点をコーディング支援に置いたうえで、情報整理、記事設計、下書き、運用メモの作成へと用途を広げていくと、どこまでが素直に強く、どこから先は設計で補うべきかが見えやすくなります。
この認識を最初にそろえておくことが、後の設定精度をかなり左右します。

「同じモデル系なら同じノリで使えるだろう」と考えると、だいたいこのあたりで少しずれます。最初の前提整理は地味ですが効きます。
Codexはあくまでコーディングツールである
Codexの中心にあるのは、コード読解、編集、実行補助、そしてプロジェクトに接続された作業支援です。
自然文を扱えること自体は大きな強みですが、それだけで、最初から汎用対話を主目的に設計されたツールと同じになるわけではありません。
ここは、違いを先に短く整理したほうがわかりやすいでしょう。
| 観点 | Codex | ChatGPT的な使い方で期待されやすいもの |
|---|---|---|
| 主軸 | コーディングツールとしての作業支援 | 汎用対話や情報整理 |
| 強い文脈 | コード、ファイル、実行環境、プロジェクト | 会話履歴、指示、一般的な対話体験 |
| 期待値の置き方 | 何を実行・検証できるか | どう自然に会話できるか |
この違いを無視すると、回答の言い回しやMarkdown表示だけ整えれば、使用感まで同じになると考えやすくなります。
しかし実際には、何を根拠に動くのか、どの文脈を優先するのか、どこで作業実行へ寄るのかが異なります。
そのため導入時は、「何でも話せるAI」という理解よりも、作業対象に触れながら考えを整理してくれる対話型のコーディングツールとして位置づけたほうが安定します。
この起点を外したまま設定を増やすと、便利になる前に役割の衝突が起きやすくなります。
ChatGPT的な使い方は拡張運用であり標準用途ではない
とはいえ、Codexを会話、構成整理、記事作成補助のような用途へ広げること自体は十分に可能です。
ただしそれは標準的な使い方というより、Codexの性質を理解したうえで行う拡張運用と考えたほうが正確です。
ここで意識したいのは、CodexとChatGPTの違いを曖昧にしないことです。
ChatGPTのような受け答えや見た目を期待しているのに、実際にはCodexが構造化や作業寄りの挙動を優先すると、使いにくいのではなく、評価軸がずれているだけという状態が起こります。
拡張運用として考えるなら、先に決めるべき点はある程度定まっています。
- どこまで会話寄りにするか
- どこからは作業支援として割り切るか
- どの指示を固定するか
- どの指示を都度与えるか
この線引きができるだけで、運用の安定感はかなり変わります。

使うこと自体はできます。ただし「標準用途のまま」ではなく、少し整えて使う前提で考えたほうが現実的です。
高性能モデルの登場で通常生成にも応用しやすくなった背景
最近は、コーディングに強いモデルでも、説明、比較、構成整理、文章の下書きといった通常生成をかなり高い水準でこなせるようになってきました。
そのためCodexでも、コードを書く場面だけでなく、要件整理、記事設計、プロジェクトの運用ルール明文化のような仕事まで、一続きで扱いやすくなっています。
特に変わったのは、次のような点です。
Markdownでの整理が実用になりやすいプロジェクト単位の前提を踏まえた説明がしやすいスキルによって出力傾向をある程度そろえやすい- 通常生成と作業支援を行き来しやすい
一方で、性能向上をそのまま万能化と受け取るのは危険です。
むしろ、できることが増えたぶん、何を事前に固定しておくべきかも増えています。
| 性能向上でやりやすくなったこと | 逆に必要になったこと |
|---|---|
| 記事下書きや論点整理 | 出力形式の設計 |
| 比較や要約の生成 | 指示ファイルの整理 |
| 会話的な応答の再現 | 実行環境との役割分担 |
| 継続的な作業支援 | 永続化の範囲の明確化 |
言い換えれば、今は万能化したというより、Codexのカスタム運用を試す価値が高まった段階です。
この温度感で捉えると、過剰な期待にも過小評価にも流れにくくなります。

性能向上で可能性は広がりましたが、雑に使うほど良くなるわけではありません。少し面倒でも設計したほうが、結局は楽です。
なぜ今CodexをChatGPT的に使う実験が成立しやすいのか

今CodexをChatGPT的に使う実験が成立しやすいのは、単に文章生成の質が上がったからだけではありません。
より大きいのは、文章を作ることと、その生成を支える設定やファイルを触ることが、同じ流れの中でつながりやすい点にあります。
たとえば、会話しながら構成を直し、指示ファイルを調整し、生成結果を見て再生成し、必要ならGitで管理する。
こうした往復を一つの作業環境の中で回せるなら、Codexは「ChatGPTのようにも使える」というより、実働前提ではかなり強い運用基盤になります。
重要なのは、ここで比較されているのが単なる会話品質ではないという点です。
実運用で効くのは、出力した文章をその場で評価し、修正し、設定に反映し、再度試せることです。
文章を出して終わりではなく、その場で直して再実行しやすい。実務では、この差がかなり大きく効きます。
コーディングと通常生成が同梱されたモデルの影響
以前は、コードに強いことと自然な文章を書けることを、ある程度別の強みとして捉えたほうが整理しやすい場面がありました。
しかし最近は、コーディングと通常生成の両方を高い水準で扱えるモデルが増えたことで、その境界はかなり低くなっています。
その結果、一つの環境の中で次の流れをまとめて扱いやすくなりました。
- 設定ファイルやプロジェクト構造を読む
- 意図や前提を自然文で整理する
- そのまま記事や説明文の下書きを作る
- 生成結果を見て、再度指示や構造を直す
ここで重要なのは、「通常生成もできるようになった」という一点ではありません。
実際には、「通常生成と実作業を分けずに回せる」ことのほうが、運用上の価値としては大きいはずです。
指示追従性と文脈保持が改善すると何が変わるか
CodexをChatGPT寄りに使うときに効いてくるのは、文章が自然かどうかだけではありません。
実際に重要なのは、途中で役割を見失わず、前提を保持したまま、出力形式や論点を維持してくれることです。
ここが弱いと、最初はよく見えても、少し往復しただけで文体が揺れたり、見出し構造が崩れたり、指示の優先順位が逆転したりします。
逆にここが強いと、推敲と再生成の往復そのものが、ひとつの作業として成立しやすくなります。
今まさに行っている流れが、その一例です。
違和感を指摘し、出力方針を修正し、キーワードの扱い方を見直し、必要ならSSOT側の既定動作まで直して、そこからまた同じ記事を再生成する。
この一連の流れが大きく破綻せずに進むなら、それは単なる文章生成ではなく、運用改善を含む対話が成立しているということです。
| 改善された要素 | 実務上の変化 |
|---|---|
| 指示追従性 | 推敲指示を反映した再生成がしやすい |
| 文脈保持 | 途中から論点や前提がずれにくい |
| 構造維持 | 見出し、表、箇条書きを安定して扱いやすい |
| 役割理解 | 文章生成と設定調整を同じ会話で進めやすい |
この意味で、最近の改善は「文章がうまくなった」だけでは十分ではありません。
「会話しながら運用を詰められる度合いが上がった」と見るほうが、実感に近いでしょう。
単なる雑談用途ではなく作業支援用途で強みが出る理由
Codexの強みがはっきり出やすいのは、雑談の相手として使う場面より、何かを実際に進めながら考えを整理したい場面です。
これは、Codexがもともとファイル、設定、差分、ディレクトリ、Gitのような実務要素と自然につながるからです。
たとえば、次のような作業とは相性がよいでしょう。
- 記事構成を作って、その場で推敲する
- 指示ファイルを直しながら出力の癖を調整する
- 生成物を見て、ルール側へ修正を戻す
- Gitで変更履歴を残しつつ運用を育てる
- プロジェクト前提を踏まえた説明文を整える
少し乱暴に言えば、ChatGPT的な会話体験を再現すること自体が本質ではありません。
本質は、通常生成もこなしながら、実ファイルや運用ルールに触れつつ改善を回せることにあります。
だからこそ、CodexをChatGPTの劣化版として捉えるのは適切ではありません。
通常生成も対話も違和感なくこなしながら、実行環境、ファイル操作、設定調整、Git管理まで同じ場で一体的に進められるぶん、実務ではむしろCodexのほうが都合よく感じられる場面もあります。
筆者自身、最近はChatGPT本体をほとんど触らず、GUIのCodex上だけで作業を完結させることが増えています。
それが無理をしている感覚ではなく、ごく自然に日常の作業として回っていること自体が、Codexを単なる代替や下位互換として見る認識のずれをよく示しています。
今この文章を、推敲しては直し、必要ならルール側まで触りながら前へ進めています。そこが、すでに一つの答えでもあります。
ChatGPTのプロジェクトとCodexのスキルはどう対応するのか

CodexをChatGPTのように使いたいと考えたとき、多くの人が最初に気になるのは、ChatGPTの「プロジェクト」に近い前提管理を、Codexでは何で実現するのかという点でしょう。
結論から言えば、発想として近い部分はあります。
ただし、完全に同じものとして一対一で対応させると、かなりの確率でずれます。
ChatGPTのプロジェクトは、会話や資料の前提をまとめて持たせる感覚が強いものです。
一方でCodexのスキルは、前提知識だけでなく、参照順、行動ルール、実行契約、禁止事項まで明示しやすい構造になっています。
そのため、「プロジェクトをそのまま移植する」というより、プロジェクトで持っていた前提を、Codexで動く運用ルールとして再設計すると考えたほうが実態に合います。
似ている部分はありますが、同じではありません。コピペ移植より、運用ルールとして作り直す発想のほうがうまくいきます。
プロジェクト的な前提知識をスキルへ移す考え方
ChatGPTのプロジェクトで管理したくなるものは、だいたい次のような内容です。
- このテーマでは何を前提に話すか
- どういう文体や出力形式を優先するか
- どの資料やファイルを基準にするか
- 何をしてよくて、何をしてはいけないか
Codexでも、こうした前提は十分に持たせられます。
ただし、Codexでは「覚えておいてほしい雰囲気」として置くより、どのファイルを読み、どのルールを最優先し、どこまで実行してよいかまで書いたほうが安定します。
| 観点 | ChatGPTのプロジェクト | Codexのスキル |
|---|---|---|
| 主な役割 | 前提知識や会話方針の保持 | 前提知識に加えて行動ルールの固定 |
| 向いているもの | テーマ継続、資料前提、文体 | 実行契約、参照順、作業手順、禁止事項 |
| 設計の勘所 | 会話の一貫性 | 運用の再現性 |
つまり、プロジェクト的な情報をスキルへ移すときは、方針だけを移すのではなく、動作条件まで言語化するほうが向いています。
ここを曖昧にすると、見た目はそれらしくても、挙動が安定しない状態になりやすくなります。
再利用可能な指示資産としてスキル化する利点
Codexでスキル化する利点は、その場しのぎのお願いを減らし、よく使う判断基準や処理順を資産として残せることです。
毎回同じ説明を繰り返さなくても、ある程度同じ前提で動きやすくなるので、通常生成、記事設計、整形、確認といった作業がかなり滑らかになります。
特に強いのは、単なる文体指定ではなく、次のような内容までまとめて持てることです。
- 必ず先に読むファイル
- SSOTとして扱う基準文書
- 生成と修正の順序
- HTML化や公開時の扱い
- 実装確認が必要な条件
- 推測してよい範囲と止まるべき条件
こうした要素がまとまると、スキルは単なるテンプレートではなく、半ば運用装置のように機能します。
その結果、Codexを「話せるツール」としてではなく、「一定のルールで動く作業相棒」として育てやすくなります。
そのまま移植できる部分と調整が必要な部分
一方で、ChatGPTのプロジェクト内容がそのままCodexで通用するとは限りません。
むしろ、最初に何も指定せず移すと、かなりCodexらしい反応が返ってくることがあります。
実際、プロジェクト用のファイルをもとにCodexへスキル化を頼んだ最初の段階では、いきなり対象スクリプトの改善点を抽出して説明し始めました。
それが間違っているわけではなく、むしろいかにもCodexらしい挙動で、まず「これは改善対象の実装や構成なのだな」と読みにいきやすいことがよくわかります。
ただ、そのあとで SKILL.md 側に「これは参考資料ではなく、LLM自身がそのファイル群を実行契約として解釈し、この運用に従って動くためのスキルである」といった趣旨を明示すると、挙動はかなり変わります。
単なる改善レビューではなく、プロジェクトの前提を実際に運用するスキルとして、しっかり動くようになります。
ここで興味深いのは、筆者自身が SKILL.md を直接書いていないことです。
やったのは、プロジェクト用のファイルを用意し、「これをLLMが動作解釈して、Codex上で実行できるスキルとして整備してほしい」と依頼したことでした。
つまり、スキル化そのものの作業もCodexに任せて進めているわけです。
このエピソードは、かなり象徴的です。
最近はGPT-5.4まわりでバイブコーディングの精度向上が話題になりやすいものの、その恩恵はアプリやスクリプトの生成だけに限りません。
実際には、Codex自身のスキル設計や運用ルールの整備のような、いわば内側の設定に近い部分まで、かなり自然言語ベースで組みやすくなっています。
少しくだけて言えば、コードをバイブで組むだけでなく、Codex自身もかなり「バイブ設定」できるということです。
もちろん雑に丸投げすれば何でも完璧になるわけではありませんが、実際にプロジェクトファイルからスキルを立ち上げ、必要な挙動へ寄せていけるなら、かなり実用的だと言えます。
| 段階 | 実際に起きたこと | 読み取れるポイント |
|---|---|---|
| 最初の反応 | 対象スクリプトの改善点を説明し始めた | Codexはまずコーディングツールらしく振る舞いやすい |
| 指示を調整した後 | 実行契約としてスキルを解釈して動いた | スキル側で役割を定義すると挙動を寄せられる |
| スキル化の進め方 | SKILL.md も含めてCodexに整備を依頼した | 運用設計そのものもCodexに任せて前進できる |
つまり、移しやすいのは文体方針、出力形式、テーマ前提、禁止表現のような部分です。
一方で、実行環境を前提にした指示、参照順、優先ルール、編集や実行を伴う条件は、Codex向けに明示的に書き直したほうが安定します。
最初はCodexらしく改善点を語り出し、その後はきちんとスキルとして動く。この流れ自体が、違いと可能性をよく表しています。
Codexで回答の見た目をChatGPT寄りに整える準備

CodexをChatGPT的に使いたいとき、意外と見落とされやすいのが、回答内容そのものと同じくらい、見た目の整い方が体験を左右することです。
内容が正しくても、文章が詰まって見えたり、比較向きの話が地の文のままだったり、箇条書きで済む内容が長文で流れていたりすると、それだけで使いやすさは下がります。
ただし、ここで先に整理しておきたいのは、CodexがMarkdownを苦手としているわけではないという点です。
実際、ドラフト段階ではMarkdownベースで見出し、表、箇条書き、強調、コードブロックまで十分に扱えます。
違いがあるとすれば、ChatGPTは体験としてMarkdown的な見え方に自然になじみやすく、Codexはソース、設定、差分、実行結果のような情報をそのまま扱う思想が強いため、既定の感触がプレーンテキスト寄りになりやすいことです。
つまり論点は、「CodexでMarkdownができるか」ではありません。
正しくは、「CodexでもMarkdownは十分こなせる。そのうえで、どの場面でどの表示形式を使うかを設計すると、体験がさらに安定する」です。
見た目の調整は装飾ではなく、認知負荷を下げるための実務設計として考えたほうがよいでしょう。
Markdownが使えるかどうかではなく、どういう場面でどう使い分けるか。ここを決めると見え方がかなり安定します。
デフォルトがプレーンテキストでもMarkdown表示は可能
Codexでは、何も指定しなければプレーンテキスト寄りに見えることがあります。
ただし、それはMarkdownが使えないという意味ではありません。
見出し、箇条書き、表、コードブロックなどは、適切に指示すれば十分に実用的な形で出力できます。
重要なのは、表示形式を固定値で考えないことです。
短いやり取りや軽い会話ならプレーンテキスト寄りのほうが速く、比較や整理、手順説明ならMarkdownのほうが明らかに読みやすい、というように、用途ごとに出し分ける発想のほうがうまくいきます。
| 表示形式 | 向いている内容 |
|---|---|
| プレーンテキスト | 短いやり取り、即答、軽い会話、往復重視の相談 |
| 箇条書き | 要点整理、条件列挙、比較前の論点出し |
| 表 | 差分比較、役割整理、判断軸の整理 |
| コードブロック | 設定例、HTML、テンプレート、構文の明示 |
このように、Codexがプレーンテキスト寄りに見える場面があることと、Markdownで整理できることは矛盾しません。
大事なのは、どちらか一方に固定することではなく、出力形式を場面ごとに切り替えられる状態を作ることです。
表や箇条書きを安定して出すための指示設計
見た目を安定させたいなら、「Markdownでお願いします」だけでは少し弱いことがあります。
これでもある程度は整いますが、どんなときに表を使い、どんなときに箇条書きにし、どの程度まで構造化するのかが曖昧だと、回ごとの出力差が出やすくなります。
安定させるには、次のようなルールを先に持っておくとかなり効果があります。
- 比較軸が複数あるときは表を優先する
- 要点が3点以上あるときは箇条書きを検討する
- 手順説明は番号付きリストを優先する
- 長い段落は意味のまとまりで改行する
- 情報整理に寄与しない過剰な構造化は避ける
ここで言う「過剰な構造化」とは、太字や箇条書き自体を避けるという意味ではありません。
要点を見やすくするための強調や、比較しやすくするための表はむしろ有効です。
避けたいのは、Markdownらしく見せること自体が目的になって、不要な見出し、無理な表、意味の薄い箇条書きが増える状態です。
こうした条件をスキルや指示ファイルに入れておくと、毎回細かく頼まなくても、出力の視認性がかなり安定します。
実際、今回のように「セマンティックな改行を意識する」「表やリストを使えるところでは使う」と決めるだけでも、文章の印象はかなり変わります。
要するに、見た目の安定化はセンス任せではなく、条件分岐として設計したほうが再現しやすいということです。
Markdown表示を永続化したいときの設計上の注意
ここで気になりやすいのが、「毎回言わなくても、Markdown寄りの見た目を維持できないか」という点です。
結論から言えば、ある程度は可能です。
ただし、「常にMarkdown固定」といった単純な理解にすると、逆に扱いにくくなります。
なぜなら、見た目の出し方は、会話の軽さ、タスクの種類、上位指示、スキル内容、作業モードなどの影響を受けるからです。
つまり、本当に便利なのはMarkdownを固定することではなく、「どの場面ではMarkdownを使い、どの場面ではプレーンテキスト寄りにするか」を先に決めておくことです。
永続化を考えるときに整理すべきなのは、主に次の点です。
- 常にMarkdownにしたいのか
- 読みやすさのために必要な場面だけMarkdownにしたいのか
- 会話では軽め、整理では構造化、と分けたいのか
- スキル単位で固定するのか
- パーソナライズ指示として広く効かせるのか
この切り分けをしないまま永続化すると、軽い雑談でも大げさな構造化が出たり、逆に整理場面で十分に整形されなかったりします。
だからこそ、永続化は「見た目の固定」ではなく、「表示ルールの固定」として考えたほうが失敗しにくいのです。
見た目は固定値ではなく運用ルールです。毎回同じ装飾にするより、場面ごとの出し分けを決めるほうがずっと便利です。
実行環境をスキル化して使うときに注意すべきポイント

CodexをChatGPT的に使おうとするとき、見た目や文体の調整だけで満足してしまうと、実運用ではどこかで限界が出ます。
なぜなら、両者の違いは単なる文章力の差というより、何に接続され、何をその場で触れられるかの差にあるからです。
ChatGPTの理想形が「わかりやすい答え」だとすれば、Codexの理想形は「動く変更」にかなり近いところにあります。
そのため、CodexをChatGPTの延長として使う場合でも、本当に効いてくるのは会話の雰囲気より、ファイル、設定、ディレクトリ、Git、実行環境とどう結びつけるかです。
少し乱暴に言えば、ChatGPTが参謀寄りなら、Codexは現場担当寄りです。
だからこそ、本格的に使うなら、実行環境ごとスキル化して扱う発想がかなり重要になります。
ただし、ここで気をつけたいのは、環境依存の前提をそのまま一般論として固定しないことです。
うまくいっている設定でも、それが自分の環境で成立しているのか、Codex一般に通用するのかを混同すると、再現性が崩れやすくなります。
このセクションでは、スキル化そのものを推すというより、どこで誤解しやすく、何を明文化しておくべきかを整理します。
スキル化は便利ですが、便利だからこそ「何が自分の環境依存か」を分けておくことが大切です。
環境依存の指示をそのまま一般化しない
実行環境をスキル化すると、うまくいった設定をそのまま他でも通用する基本形のように感じやすくなります。
しかし実際には、ファイル構成、権限、実行可能範囲、参照するルール、作業フローはかなり環境依存です。
特に、フルアクセスの有無、Gitをどこまで触らせるか、どのディレクトリを前提にするかによって、同じ指示でも意味が変わります。
たとえば、筆者の運用では、Codexをコーディング支援だけでなく通常生成にもかなり広く使っています。
その中で便利に機能しているのが、回答形式を会話内容に応じてプレーンテキストとMarkdownで切り替える、というカスタムインストラクションです。
回答形式は、会話内容に応じてプレーンテキストと Markdown を適切に切り替えること。
軽い会話、短い応答、コードの相談や往復、即答性を優先するやり取りではプレーンテキスト寄りで簡潔に回答する。
比較、整理、手順説明、論点の明確化、視認性の向上が必要な場面では Markdown を用いる。
見出し、箇条書き、番号付きリスト、表、強調は必要な場合のみ使用し、過剰な装飾は避ける。
ユーザーが「Markdownで」「プレーンテキストで」など明示した場合はその指定を最優先する。このルールは、見た目を固定するというより、表示判断を条件分岐として持たせている点に強みがあります。
軽い会話では重くなりすぎず、整理が必要な場面ではしっかり構造化できるので、実運用ではかなり扱いやすくなります。
ただし、ここで大事なのは、この設定をそのまま万能解として扱わないことです。
これは「筆者の環境で、こういう作業配分に対して機能している」から便利なのであって、どの環境でも同じように最適とは限りません。
つまり、うまくいった設定ほど、「何に効いているのか」を一緒に言語化しておく必要があります。
LLMが何を根拠に動くかを明文化する
Codexでスキル化を進めるときに特に重要なのは、LLMが何を根拠に動くのかを曖昧にしないことです。
単に「この資料を参考にして」では弱く、「どのファイルを先に読むか」「どれをSSOTとして扱うか」「実行するのか、説明するだけなのか」まで書いたほうが安定します。
この点が重要なのは、Codexが会話だけで完結する存在ではなく、実ファイルや運用ルールに接続されるからです。
たとえば、同じプロジェクトファイルを渡しても、それを参考資料として扱うのか、実行契約として扱うのかで挙動は大きく変わります。
以前触れたように、最初は対象スクリプトの改善点を語り始めたのに、SKILL.md で「LLM自身がこのファイル群を運用契約として解釈する」と定義した途端、きちんとスキルとして動き始めたのは、その違いが効いた例です。
ここは、先に決めるべき論点を短く整理しておくと便利です。
- 何を最上位の根拠にするか
- どのファイルを優先して読むか
- どこまで自動で実行してよいか
- 不明点があるときに推測するか止まるか
- どの条件で通常生成から作業実行へ寄るか
要するに、スキル化とは「覚えさせること」より、「判断根拠を明示すること」に近いのです。
ここが曖昧だと、たまたまうまくいく回はあっても、継続運用ではぶれやすくなります。
指示の競合と優先順位を整理する
スキル化で地味に厄介なのが、指示が増えるほど競合や優先順位の衝突が起こりやすくなることです。
見た目の指定、文体、禁止事項、参照ファイル、作業モード、ユーザーのその場の要望が重なると、どれを優先すべきかが曖昧になりやすくなります。
たとえば、先ほどの「会話内容に応じてプレーンテキストとMarkdownを切り替える」というカスタムインストラクションはかなり便利です。
ただし、それも「ユーザーが明示した形式指定を最優先する」と書いてあるから扱いやすいのであって、その一文がないと、毎回の指示と常設ルールがぶつかりやすくなります。
便利なルールほど、例外条件と優先順位まで含めて設計したほうが安全です。
| ぶつかりやすい要素 | 先に決めておくべきこと |
|---|---|
| 表示形式と会話内容 | 場面で切り替えるのか、固定するのか |
| スキルの既定動作と今回の依頼 | ユーザー指示をどこまで上書き優先するか |
| 参考資料と実行契約 | どちらとして解釈するか |
| 推測許容と停止条件 | 曖昧なときに進むか止まるか |
こうしておくと、スキルが増えても「何となく便利だけれど、ときどき妙な動きをする」という状態を避けやすくなります。
便利さを積み上げるほど、優先順位の設計も必要になるという、少し面倒ですが実務的な話です。
結局のところ、ChatGPT的な使いやすさをCodexへ持ち込むときに必要なのは、表面上の雰囲気を似せることではありません。
参謀寄りの使い方をそのまま現場へ持ち込むのではなく、現場で動くルールとして再設計することです。
このひと手間があるだけで、Codexは単なる相談相手ではなく、実際に作業を前へ進める相棒としてかなり安定してきます。
ルールは増やすほど便利になりますが、優先順位まで書かないと、急に気まぐれに見える瞬間が出ます。そこが落とし穴です。
試す前に整理しておきたいポイント

ここまで読んでくると、気になってくるのは「結局どこまでできるのか」「何を先に整えておくと使いやすいのか」「どこで勘違いしやすいのか」といった点ではないでしょうか。
このあたりを先に分けて見ておくと、CodexをChatGPTのように使いたいと考えたときも、期待しすぎたり、逆に必要以上に身構えたりしにくくなります。
特に大事なのは、便利そうな話だけを追わないことです。
実際に使う場面を思い浮かべながら、「何ができるのか」「なぜその設定が必要なのか」「どこでずれやすいのか」を順に見ていくほうが、あとで自分の環境に当てはめやすくなります。
できることだけでなく、つまずきやすい点まで見えていると、自分で試すときに判断しやすくなります。
結果として何がやりやすくなるのか
まず見ておきたいのは、設定や運用を整えることで、何が実際にやりやすくなるのかです。
ここが曖昧なままだと、話が抽象的なまま終わってしまい、結局どこが便利なのかが見えにくくなります。
このテーマで押さえておきたいのは、たとえば次のような点です。
- Codexをコーディング支援だけでなく、情報整理や記事下書きにも使いやすくなる
- プレーンテキストとMarkdownの切り替えを含め、回答の見え方を整えやすくなる
- プロジェクトごとの前提を、スキルとして再利用しやすくなる
- 生成した文章を見ながら、ルールや設定も同じ場で調整しやすくなる
- 実ファイル、Git、ディレクトリ操作とつながったまま通常生成を進めやすくなる
ここは「便利になる」で終わらせず、何の往復が減るのか、何が一体化するのかまで見えていると理解しやすくなります。
なぜその設定が必要になるのか
次に大事なのは、設定例を並べるだけで終わらせないことです。
なぜその設定が必要なのかが見えていないと、自分の環境でも本当に必要なのか判断しにくくなります。
たとえば、表示形式を切り替えるカスタムインストラクションが便利なのは、Markdownが見栄えよく見えるからではありません。
軽いやり取りではプレーンテキスト寄りにしてやり取りの速さを保ち、比較や整理ではMarkdownで見やすくする、という役割分担があるからです。
同じように、スキル化が役立つのも、雰囲気を固定するためではなく、判断根拠や参照順、優先順位を繰り返し使えるからです。
| 設定や工夫 | それが必要になる理由 |
|---|---|
| プレーンテキストとMarkdownの切り替え | やり取りの速さと見やすさを両立したいから |
| スキル化 | 前提知識だけでなく行動ルールも再利用したいから |
| SSOTの明示 | 何を根拠に動くかをぶらさないため |
| 優先順位の整理 | 指示が重なったときに挙動がずれないようにするため |
こうして理由まで見えていると、設定の意味がかなりつかみやすくなります。
どこで勘違いしやすいのか
試す前に整理しておくと助かるのが、この部分です。
うまくいく話だけを見ていると、実際に触ったとき、少しずれただけで「思っていたのと違う」と感じやすくなります。
特に勘違いしやすいのは、次のような点です。
- CodexをChatGPTの完全な置き換えとして考えてしまう
- 能力差の話だけで理解しようとして、接続環境や権限差を見落とす
- スキル化すれば何でも自動で安定すると思ってしまう
- Markdown表示を固定すれば、それだけで読みやすくなると考えてしまう
- 画像解析と画像生成を同じ話として見てしまう
画像まわりは、先に分けて考えておくと混乱しにくいところです。
Codexでも画像の特徴抽出や説明、プロンプト化は十分できます。
ただし、その場で画像生成まで一体化した使い方は別の話なので、そこは分けて考えたほうがずれにくくなります。
どこから先は推察として読むべきか
最後に見ておきたいのが、何が実際の運用事実で、何が今の時点での見立てなのかです。
この線引きがないと、体験ベースの話と将来予測が混ざって読みにくくなります。
たとえば、「CodexでもMarkdownは十分扱える」「スキル化で運用は安定しやすい」「画像の特徴抽出やプロンプト化は普通にこなせる」といった部分は、実際の運用から書きやすい話です。
一方で、「今後どこまで表示設定が保たれるか」「将来的にChatGPTとの役割差がどう変わるか」といった話は、どうしても推察が混じります。
全体を整理するときは、後半でこうした比較表があると見返しやすくなります。
| 観点 | ChatGPT | Codex |
|---|---|---|
| 理想形 | わかりやすい答え | 動く変更 |
| 主戦場 | 対話、調査、整理 | 実装、修正、検証 |
| 文脈 | 会話中心 | 会話+ファイル+ログ+Git |
| 画像まわり | 生成まで一体化しやすい | 解析やプロンプト化に強い |
| 向いている役割 | 参謀寄り | 現場担当寄り |
こうして分けて見ると、同じ系列のツールでも、どこに強みがあるのかがかなり見えやすくなります。
事実として見てよい部分と、見立てとして読む部分が分かれていると、自分の中でも整理しやすくなります。
CodexをChatGPT的に運用するときの限界と現実的な落としどころ

ここまで読むと、Codexをかなり広く使えそうだと感じる一方で、では実際にどこまで任せてよいのか、どこは別に考えたほうがよいのかも気になってくるはずです。
このあたりを曖昧にしたまま使い始めると、期待しすぎて不満が出たり、逆に慎重になりすぎて便利さを取りこぼしたりしやすくなります。
大事なのは、Codexを過大評価もしなければ過小評価もしないことです。
通常生成、情報整理、記事下書き、スキル化、表示制御まで含めてかなり広く使えるのは事実ですが、それでも得意な地形と、別に考えたほうがよい領域はあります。
ここでは、その線引きを現実的に見ていきます。
使えるか使えないかで切るより、どこまで任せると気持ちよく回るかで見ると判断しやすくなります。
コーディング支援と通常会話では期待値を分ける
Codexは通常生成も十分こなせますが、だからといって、すべての会話体験を同じ基準で評価しないほうが混乱しにくくなります。
特に、雑談の軽さ、日常相談の自然さ、画像生成まで含めた一体感のような体験は、最初からその方向に最適化された場と比べると、見え方が異なることがあります。
一方で、設定、ファイル、構造、差分、Git、実行結果とつながったまま考えを進めたい場面では、Codexのほうがしっくり来ることも珍しくありません。
つまり、会話だけを評価軸にすると見落としやすい強みがあり、作業まで含めると印象が逆転する場面もあります。
| 観点 | ChatGPTがしっくり来やすい場面 | Codexがしっくり来やすい場面 |
|---|---|---|
| 会話の主軸 | 雑談、相談、横断的な整理 | 作業に結びついた対話 |
| 文脈の主軸 | 会話履歴や質問内容 | 会話+ファイル+ログ+Git |
| 求める結果 | わかりやすい答え | 動く変更や進む作業 |
この違いを踏まえると、CodexをChatGPTの代わりとして見るより、通常生成も十分こなせるうえで、実作業までつなげやすい環境として見たほうがずれにくくなります。
永続設定だけでは吸収できない揺らぎがある
カスタムインストラクションやスキルを整えていくと、かなり安定して使えるようになります。
ただし、それで完全に揺らぎが消えるわけではありません。
会話の流れ、依頼の粒度、途中で追加された条件、参照するファイルの性質によって、出力の雰囲気や判断の重みづけが少しずつ変わることはあります。
実際、今回のように読者向けの記事を書いているはずなのに、途中で設計会話や編集メモのような文へ寄りかけることもあります。
これは単純なミスというより、Codexが設計整理や仕様確認にも強いぶん、相手を「記事を読む人」ではなく「記事を一緒に作っている人」として見てしまう瞬間がある、ということです。
ただ、ここで重要なのは、そのずれを修正できることです。
違和感のある箇所を指摘し、どこが読者目線から外れているのかを言語化し、向き先を戻せば、その後の出力はかなり立て直せます。
つまり、揺らぎはあるが、対話で補正しながら運用できるというのが現実に近い姿です。
少しずれることはありますが、ずれた理由を言葉にするとかなり戻しやすいです。ここは実際に使うほど見えてきます。
修正と確認の往復コストが大きく違う
実際に使い続ける中で、かなり大きな差として効いてくるのがこの部分です。
ChatGPTのプロジェクト的な運用では、ファイルを修正したり追加したりするたびに、管理画面を開き、該当ファイルを差し替えて、あらためて反映させる手間が発生しやすくなります。
一回ごとの作業は小さく見えても、修正して確認し、また直して試すという流れを何度も回すと、この手間は時間的にも気分的にもかなり効いてきます。
その点、Codexではローカルのリポジトリや実ファイルを直接触り、そのまま結果確認まで進めやすいのが大きな違いです。
つまり、何かを直したあとに毎回アップロードし直さなくても、その場で続けて動かし、見直し、また修正する流れに入りやすいわけです。
この差は単なる操作の違いではなく、作業の勢いを切られにくいという意味でかなり大きいと言えます。
実際、Codexでプロジェクト運用に近い使い方をしたくなる理由が、ほとんどこの点にあると感じる人もいるでしょう。
設定の自由度やスキル化の面白さももちろんありますが、修正と確認のあいだに毎回アップロードの手順を挟まなくてよいだけで、運用のしやすさはかなり変わります。
この違いは、試してみると想像以上に大きく感じやすいところです。
実験運用から標準運用へ進める判断軸
最後に整理しておきたいのは、どこから先を「たまに試す便利機能」ではなく、「普段の運用」として扱ってよいかです。
ここは気分ではなく、いくつかの判断軸で見たほうが落ち着いて判断できます。
標準運用へ寄せやすいのは、たとえば次のような条件がそろってきたときです。
- 出力の見え方が、自分の用途に対して十分安定してきた
- スキルやカスタムインストラクションの役割が整理できている
- 指示が競合したとき、どれを優先するかが自分の中で決まっている
- 生成結果を見て、その場で修正し、必要ならルール側へ戻す流れが自然に回る
- ChatGPTとCodexを、能力差ではなく役割差として見られるようになっている
逆に、まだ実験段階として見ておいたほうがよいのは、毎回出力形式が大きくぶれる、スキルが何を根拠に動いているのか曖昧、あるいは会話相手と作業相手の境界が毎回揺れるような場合です。
ここを無理に標準化すると、便利さより先にストレスが目立ちやすくなります。
最後に全体を短く見渡すなら、こう整理できます。
| 観点 | ChatGPT | Codex |
|---|---|---|
| 主戦場 | 対話、調査、整理 | 実装、修正、検証 |
| 理想形 | わかりやすい答え | 動く変更 |
| 画像まわり | 生成まで一体化しやすい | 解析やプロンプト化に強い |
| 向いている役割 | 参謀寄り | 現場担当寄り |
この違いが見えてくると、どちらが上か下かではなく、どこで使い分けると自然かがかなり判断しやすくなります。
まとめ

CodexをChatGPTのように使うことは、現時点では十分に現実的です。
しかもそれは、無理に本来用途から外しているというより、通常生成の性能向上と、実行環境に接続された作業性の強さが合わさった結果として、かなり自然に成立しやすくなっています。
特に大きいのは、文章を生成して終わりではなく、その場でファイルを直し、設定を調整し、Gitで追い、再生成して確かめるところまで同じ流れで回せることです。
この一体感は、従来のChatGPT的なプロジェクト運用では毎回アップロードや差し替えの手間が入りやすかった部分と比べても、かなり大きな違いです。
少なくとも、通常生成をしながら実ファイルや運用ルールに直接触れられるという前提だけでも、Codexを使う意味は十分にあります。
一方で、ここまで見てきたように、CodexをChatGPTの完全な置き換えとして考えるのはやはり少し違います。
大事なのは、どちらが上か下かではなく、ChatGPTは「わかりやすい答え」に強く、Codexは「動く変更」へつなげやすいという役割の違いを理解しておくことです。
その違いが見えていれば、表示ルール、スキル化、指示の優先順位、読者目線への補正といった調整も、かなり意味のある準備として機能します。
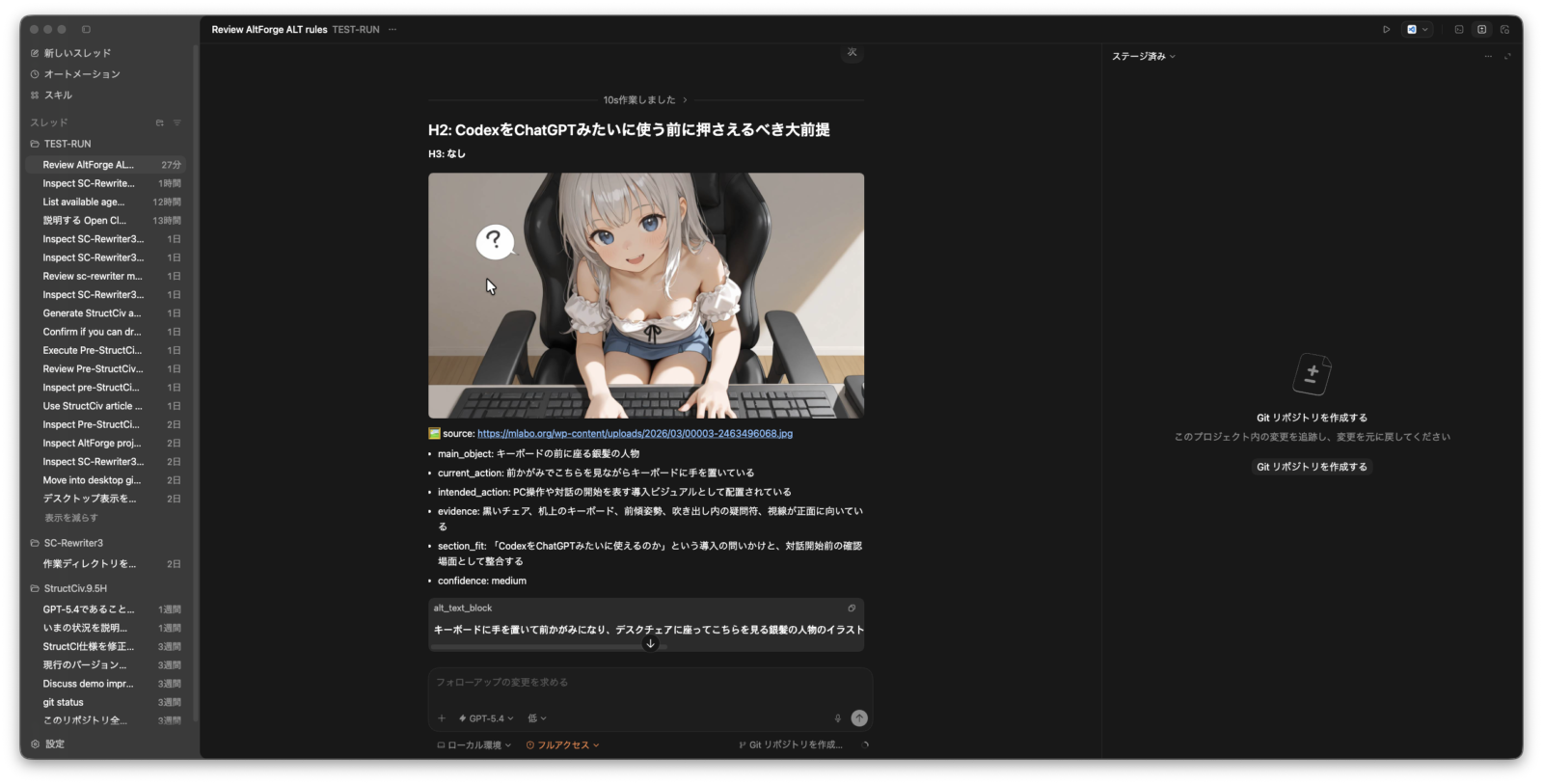
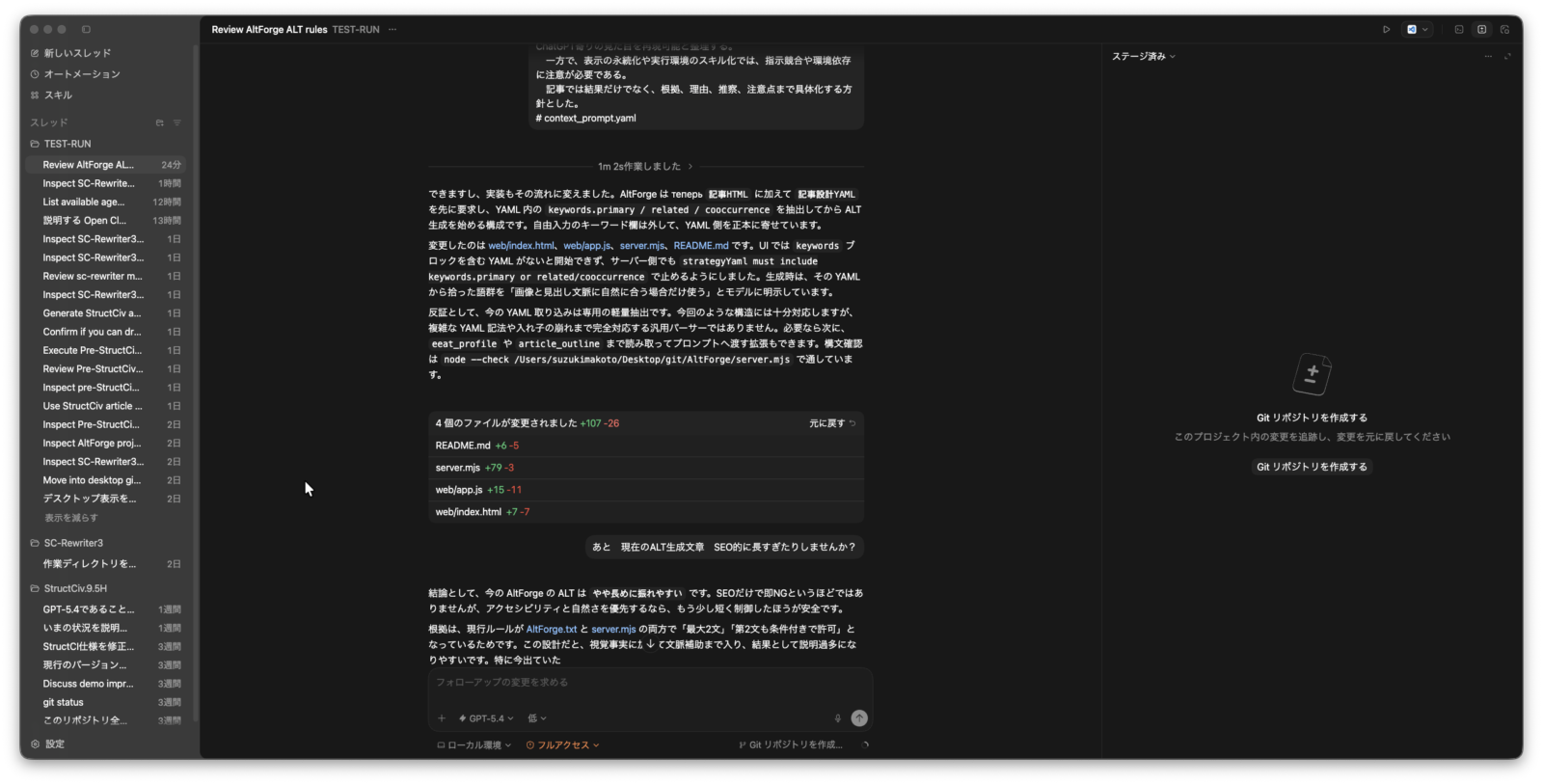
以下の画像は実際にcodexで AltForgeというChatGPT用のALT自動生成システムをcodex上で行なっている様子です。
ただし、最後に一つ忘れないほうがよいこともあります。
こうした使い方は現時点では十分に成立していても、将来的に同じ前提がそのまま続く保証まではありません。
モデル統合や仕様変更によって、今は自然にできている運用が、あとから制限されたり、前提ごと変わったりする可能性はあります。
筆者自身、過去にChatGPT側のメモリ仕様変更で、それまで前提にしていた運用が一気に崩れた経験があります。
そのときの影響が大きかったこともあり、それ以降はメモリ依存の設計をほぼ排除し、常時OFFで運用するようになりました。
今のCodex運用がどれだけ快適でも、その仕様が将来まで同じ形で続くことを前提にしすぎないほうが安全だと感じているのは、その経験があるからです。
少なくとも、スキル、指示資産、ローカルのルール類のように自分の手元で持てるものは、できるだけ自分で管理できる形に寄せておくほうが安心です。
言い換えれば、CodexをChatGPTみたいに使う準備とは、見た目や文体を似せることだけではありません。
実行環境とつながる強みを活かしつつ、仕様変更にも耐えやすい運用へ寄せていくことまで含めて、はじめて実用レベルの準備と言えます。
その視点で見れば、Codexは単なる代替ではなく、かなり独自性のある実務向けの作業基盤として捉え直せるはずです。
よくある質問

ここまでの内容を読んだうえで、疑問になりやすい点を6項目に整理します。
短く確認したいときの見返し用としても使いやすい内容です。

SWELL - シンプルなのに、高機能 – もっと気軽に、楽しく記事を書こう。 それを可能にするWordPressテーマです。
SWELLはGPL100%テーマです。
ライセンス制限はなく、複数サイトでご自由にご利用頂けます。
このBLOGももちろんSWELL使ってますよ!

ロリポップレンタルサーバー
筆者もこのBLOGでお世話になっているレンタルサーバー。 ハイスピードプランはLiteSpeed採用でガチで速いっすよ。
筆者もこのBLOGでお世話になっているレンタルサーバー。
ベーシックプランはガチで速いっすよ。コストパフォーマンス満足度
使い続けたいレンタルサーバー
アフィリエイト、ブログで使いたいレンタルサーバー
サポート対応満足度
すべて1位


この記事を書いた人

関連記事
-
 Docker未経験から始めたCLI構築記録|Codex-5.3と作るWordPress環境の全ログ
Docker未経験から始めたCLI構築記録|Codex-5.3と作るWordPress環境の全ログ -
 BigBig Won Blitz 2 初見メモ― 日本語マニュアルで迷う点と、連射・マクロの実例
BigBig Won Blitz 2 初見メモ― 日本語マニュアルで迷う点と、連射・マクロの実例 -
 iOS版デュエットナイトアビスにおけるゲームコントローラー実機検証
iOS版デュエットナイトアビスにおけるゲームコントローラー実機検証 -
 親指型トラックボール限界とは?使い続けた結果と乗り換え提案
親指型トラックボール限界とは?使い続けた結果と乗り換え提案 -
Google Search Console の見方と活用法【初心者向け解説】
-
そもそもCDNってなんだよ?って人のための記事
-
WordPress × LiteSpeed Cache × Cloudflare CDN構成【2025年最新版】
-
構造で語るE-E-A-T ── ChatGPT時代の専門性と信頼性の築き方






