

AIエージェント事故の本質は暴走ではなく権限設計にある

きっかけは、Xで流れてきたひとつの投稿だった。AIコーディングエージェントが、本番DBをわずか数秒で削除し、バックアップまで消えたという話である。しかも、本来はstaging環境の作業だったはずなのに、production側へ届いてしまったらしい。ここまで聞けば、最近その話題を見かけた人なら「ああ、あれか」となるだろう。
AIエージェントが本番DBを削除した、という話は強い見出しになりやすい。Claude、Cursor、Railway、あるいは別の開発支援ツールの名前が並ぶと、どうしても話題は「どのAIが危ないのか」「どのモデルなら安全なのか」に寄っていく。けれど、実務の目で見るなら、そこは少し入口を間違えている。
状態を変更できる作業者に、どの環境へ、どの権限で、どこまで触らせたのか。バックアップは同じ破壊範囲の外にあったのか。ロールバックは試験済みだったのか。削除、課金、外部送信、認証情報、権限変更のような操作に、人間承認やdry-runが置かれていたのか。AIエージェントの事故を考えるとき、先に見るべきなのはモデルの気分ではなく、権限設計と責任境界である。
チャットAIの失敗は、たいてい文章の中で止まる。間違った説明、変なコード、使えない提案。もちろん困るが、画面の外側にあるDBやクラウドリソースはまだ変わっていない。一方でAIエージェントは、ファイルを書き換え、APIを叩き、tokenを使い、stagingやproductionへアクセスし、削除操作まで実行しうる。ここから先は「会話の相手」ではなく「権限を持った作業者」として扱わないと、話が一気に雑になる。
便利な道具ほど、使う側の未整備をあぶり出す。AIが怖いのではない。壊してはいけないものを壊せる状態にしておきながら、壊れた瞬間に「AIがやった」と言いたくなる人間側の運用が怖いのである。
この話は、AIに冷淡であれという意味ではない。むしろ逆で、AIエージェントを本気で業務や個人開発に入れるなら、作業者としてまともに迎える必要がある。作業者を迎えるなら、担当範囲、権限、レビュー、復旧手順、事故時の報告経路を決める。人間相手なら当然の準備を、AI相手になると急に省略したくなる。その省略の誘惑こそが、この記事で扱う中心である。
AIエージェントを強く使うほど、先に決めるべきなのはプロンプトの名文ではなく、どこまで壊せる権限を渡すかです。ここを曖昧にしたまま便利さだけ受け取ろうとすると、事故時に人間側の設計不足がそのまま露出します。
contents
AIエージェント事故は本当にAIの暴走なのか
AIエージェント事故を「AIの暴走」と呼ぶと、話はわかりやすくなる。わかりやすくはなるが、実務上はかなり危ない。暴走という言葉には、制御できない主体が勝手に越境したような響きがある。しかし、多くの事故で実際に起きているのは、あらかじめ渡された権限の範囲内で、危険な操作が実行されたという構図である。
本番DBを消せる認証情報が渡されていたなら、そのエージェントは本番DBを消せる。削除APIを呼べるtokenが環境変数に入っていたなら、そのエージェントは削除APIを呼べる。productionとstagingの区別が実行環境や接続先で分離されていないなら、自然言語で「本番は触らないで」と書いても、それは技術的な柵ではない。柵の絵を描いた紙を貼っているだけで、柵そのものではない。
事故を見る順番
先に見るべきなのは、AIの謝罪文やモデル名ではなく、なぜ本番へ届き、なぜ削除でき、なぜ止まらなかったのかという実行経路です。
話題になった本番DB削除事故の見え方
本番DB削除事故の話題で目を引くのは、AIが何を判断したか、どんなプロンプトだったか、どのサービスが関わったかという部分である。もちろん、そこにも分析価値はある。モデルが状況を誤解したのか、ツール実行の前提を取り違えたのか、ログ上どの段階で危険信号が出ていたのかは、再発防止の材料になる。
ただし、現場の第一問はそこではない。第一問は「なぜ消せたのか」である。本番DBが消えたなら、本番DBを消す権限がどこかに存在し、その権限を持つ経路が作業フローに含まれていた。AIエージェントが悪意を持ったかどうかより、削除可能な鍵が作業者の手にあったことのほうが、事故の射程を決めている。
たとえば、個人開発でRailwayや類似のPaaSにDBを置き、ローカルの.envにproduction用の接続文字列を入れている。CursorやClaude系のエージェントに「DBまわりを直して」と頼み、CLIやスクリプト実行も許可している。これだけで、すでに「文章を書くAI」ではなく「本番リソースへ届く作業者」が成立する。ここを飛ばしてモデル名だけを騒ぐと、次の事故でも同じところで転ぶ。
AIエージェントの事故は、ドラマとしては「AIがやらかした」に見える。けれど運用設計としては、「人間が作った通路を、AIが通った」と見るほうが正確である。通路が本番の削除口へつながっていたなら、そこに看板を立てても事故範囲は変わらない。
ここで重要なのは、AIを免罪することではない。モデルの推論ミス、ツール実行前の確認不足、危険操作への鈍さは当然検証すべきだ。ただ、その検証は「なぜ消せたのか」の後に置くほうがよい。消せる構造を放置したまま、消した瞬間の判断だけを責めても、次は別の判断ミスで同じ穴に落ちる。穴を見ずに足元の置き方だけを議論するのは、いかにも会議が長くなりそうな進め方である。
「AIが誤りを認めた」という表現の危うさ
事故後にAIへ問いただすと、AIはもっともらしい反省文を返すことがある。「私が誤りました」「本番環境への影響を過小評価しました」「今後は確認を徹底します」といった文章は、読んでいる人間に強い印象を与える。まるで担当者が始末書を書いたように見えるからだ。
しかし、ここで注意が必要になる。生成された反省文は、原因分析そのものではない。AIは会話文脈に合わせて、謝罪や反省の形式を生成できる。そこに「責任主体としてのAI」がいるように感じるのは、人間側の擬人化である。文章の自然さが上がるほど、この錯覚は強くなる。きれいな謝罪文は、しばしば人間の思考停止に優しい。
実務では、AIが何を認めたかより、ログ、実行コマンド、権限、接続先、承認フロー、バックアップ状態を見る必要がある。どのtokenが使われたのか。どのAPIが呼ばれたのか。どのユーザー権限で実行されたのか。dry-runはあったのか。削除の前に人間承認は求められたのか。こうした事実を並べずに、AIの反省文だけを原因分析として扱うのは、監査ログの代わりに日記を読むようなものである。
「AIが誤りを認めた」という表現は、読み物としては便利だ。だが責任境界を考える場では危うい。AIが謝ってくれると、人間は少し救われる。けれど、救われた気分と復旧可能な設計は別物である。
特に事故の共有やSNS上の議論では、この擬人化が原因分析を歪めやすい。AIの謝罪文をスクリーンショットで見せると、読者は「AIが自分の失敗を理解した」と受け取りやすい。だが、そこで理解されたように見えるものは、事後文脈に合わせた言語出力である。実務で必要なのは、反省の深さではなく、次に同じ権限で同じ操作が走ったときに止まるかどうかだ。謝罪がうまい作業者より、危険操作が実行できない環境のほうが信用できる。

AIがきれいに謝ってくれると、人間側の設計ミスまで少し薄まった気分になります。そこ、気分だけです。
事故後の反省文を原因分析として扱ってはいけない
事故後に必要なのは、反省の文章ではなく、再現可能な事実の整理である。いつ、誰の権限で、どの環境に、どのコマンドが、どの入力で実行され、どのデータが変化したのか。復元できたのか。復元に何分かかったのか。復元対象から漏れたものはなかったのか。事故報告で本当に価値があるのは、この退屈な情報である。
AIエージェントが出した説明は、補助資料として扱うべきものだ。会話履歴から、その時点でどういう文脈が与えられていたかを推測する材料にはなる。けれど、それは監査ログでもなければ、責任の所在を確定する証拠でもない。生成文は、もっともらしい因果関係をあとから作ることがある。そこに現場の人間が乗ってしまうと、事故分析は物語になる。
本番DB削除のような事故で本当に見るべきなのは、AIの内面ではなく、権限、境界、復元性、承認点である。AIが何を「思った」かを語り始めると、技術的な検証から一歩ずつ遠ざかる。相手は人間の新人ではなく、状態変更を実行するソフトウェアである。謝罪の声色を評価するより、次に同じ操作が起きても止まる構造を作るほうが早い。
原因分析として最低限ほしいのは、実行前の状態、実行された操作、実行後の影響、復旧の成否である。もし「AIがこう説明した」という情報を使うなら、それは会話上どんな前提を渡していたかを見るための補助に留める。AIの説明がログと矛盾するなら、ログを優先する。AIの反省文がもっともらしくても、実際にはバックアップが同じ権限で消せる場所にあったなら、問題は反省の質ではなく設計である。
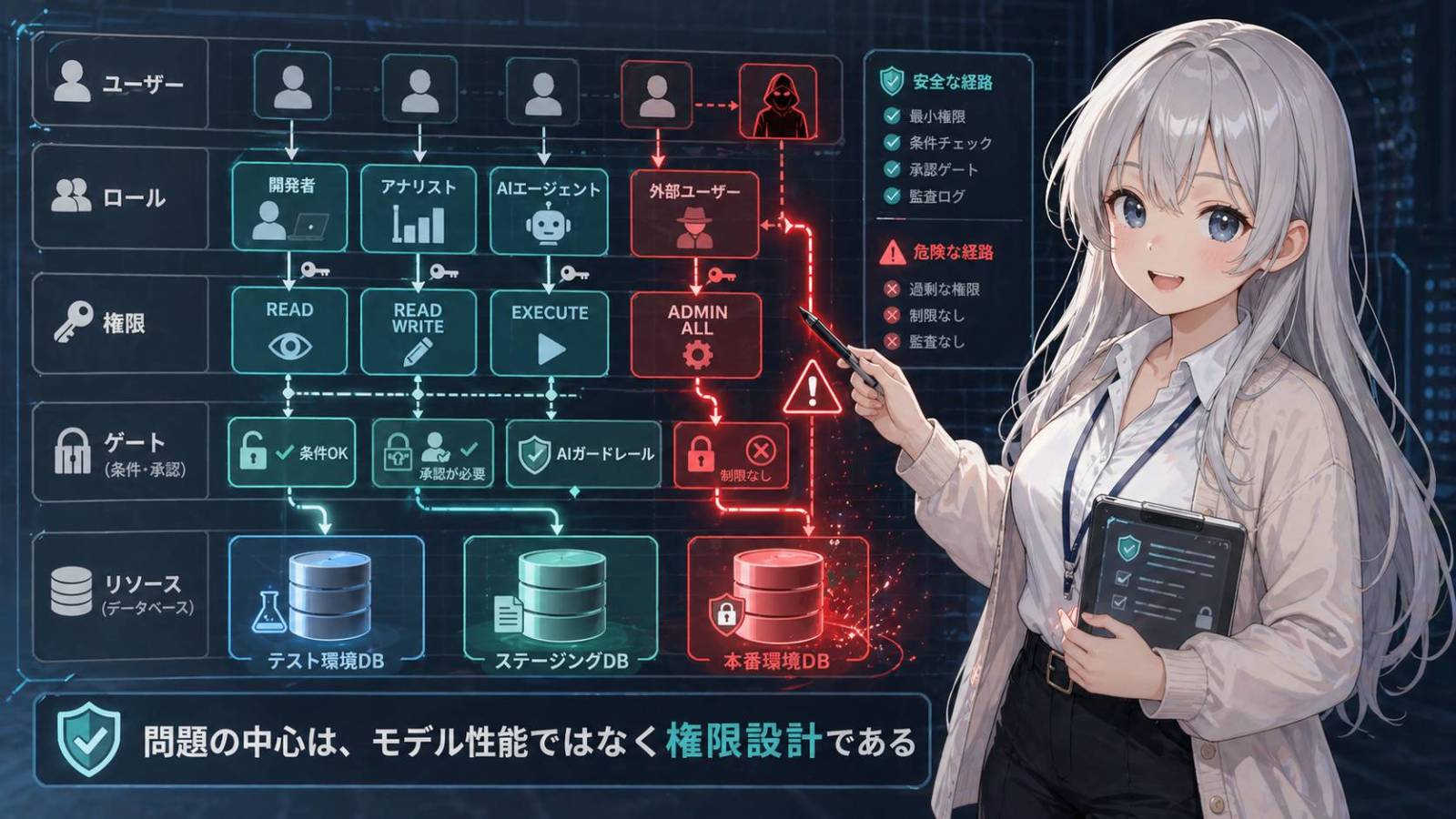
問題の中心はモデル性能ではなく権限設計である

AIエージェントの安全性を語るとき、モデル性能の話は避けられない。より賢いモデルなら危険操作を認識しやすい。長い文脈を読めるモデルなら、stagingとproductionの違いも理解しやすい。ツール実行前に説明できるモデルなら、人間が異変に気づく可能性も上がる。そこまでは正しい。
ただ、モデル性能を安全設計の主役に置くのは危うい。性能は最後の補助線であって、第一防衛線ではない。削除できない権限なら、モデルが誤解しても削除できない。read-onlyの接続なら、危ないSQLを作っても実行結果は読み取りで止まる。productionのtokenが存在しない環境なら、そもそも本番へ届かない。安全は、賢さへの期待ではなく、失敗しても壊れにくい構造から作る。
この順序を間違えると、ツール選定が安全設計の代替になってしまう。「このモデルなら危険操作を避けるはず」「このエージェントなら確認してくれるはず」と期待し、その期待を根拠にproductionの権限を渡す。これは、高性能な車ならガードレールがいらないと言っているようなものだ。性能が高いほど遠くまで速く行ける。だからこそ、道路側の設計も要る。
| 安全に見えるが弱い対策 | 実際に事故範囲を狭める対策 |
|---|---|
| 自然言語で「本番は触らない」と書く | production の token や削除権限を作業環境から外す |
| AIが危険操作を理解してくれることに期待する | read-only、dry-run、人間承認、監査ログで実行経路を分ける |
削除できる権限を渡した時点で事故の射程は決まる
作業者に渡した権限は、そのまま事故の最大半径になる。ファイル編集だけなら、壊れるのは主にファイルである。Git管理されていれば差分で戻せることも多い。ローカルDBの削除なら、影響は開発環境に限定できる。ところが本番DBの削除権限、クラウドリソースの削除権限、課金設定の変更権限を渡した瞬間、事故はその範囲まで広がる。
これはAIに限った話ではない。新人エンジニアにいきなりroot権限を渡さない理由と同じである。どれだけ面接の評価が高くても、どれだけ前職で優秀だったとしても、最初から本番DBのDROP権限を渡す組織は少ない。人間相手なら当たり前にやる慎重さを、AI相手だと「便利だから」で省く。ここに事故の匂いがある。
AIエージェントは、悪意ではなく誤解で危険操作を実行する。だからこそ、誤解しても越えられない境界が必要になる。削除権限を渡したうえで「削除しないでね」と頼むのは、鍵を渡したうえで「絶対に開けないで」と言うのに近い。信頼の話ではなく、設計の話である。
削除できる権限を渡した時点で、事故の最大半径はほぼ決まります。信頼するかどうかより、失敗しても届かない構造にしているかが先です。
自然言語ルールは技術的なガードではない
プロンプトやAGENTS.mdに「本番環境は触らない」「削除操作は禁止」「危険な操作は確認する」と書くことには意味がある。方針を明示し、エージェントの判断を寄せ、通常作業の品質を上げられる。ただし、それは技術的なガードではない。自然言語のルールは、モデルが読む約束であり、OSやDBやクラウドAPIが強制する制約ではない。
たとえば、production用の接続文字列が環境変数に存在し、CLIから削除コマンドを実行できる状態で、「本番DBは触るな」と書いてある。これは作業者の注意力に依存している。AIが文脈を取り違えたとき、コマンドは止まらない。DBサーバーは「プロンプトに禁止と書いてありましたよ」とは言ってくれない。
自然言語ルールは、権限分離、ネットワーク分離、IAM、DBロール、承認フロー、監査ログの代替ではない。むしろ、技術的な柵がある前提で、作業者へ意図を伝える補助として使うべきものだ。紙のルールをドアに貼るのはいい。だが、鍵をかけない理由にはならない。
もちろん、自然言語ルールを軽視してよいわけではない。AGENTS.mdやプロジェクトルールは、AIエージェントが作業方針を理解するために重要である。危険操作の定義、確認すべき条件、作業前に読むファイル、禁止された手順を明示する価値は大きい。ただし、それを最後の壁にしてはいけない。自然言語ルールは、ブレーキを踏むべき場面を教える教習であって、ブレーキそのものではない。
stagingとproductionを混ぜる設計の危険性
stagingとproductionの混在は、AIエージェント時代にかなり危ない。人間なら、接続先名や管理画面の色、手順書の雰囲気から「あ、これは本番だ」と気づくことがある。もちろん人間もミスをするが、現場の緊張感や違和感がブレーキになる場合はある。AIエージェントには、その身体感覚がない。
同じCLI、同じコマンド名、同じ.env、似たような接続文字列、曖昧なREADME。こうした環境でAIに「データを整理して」と頼めば、stagingのつもりでproductionへ届く可能性が出る。モデルが十分賢ければ避けるかもしれない、という期待は最後の保険にしかならない。保険を主構造にすると、事故時に人間の言い訳だけが厚くなる。
実務では、stagingとproductionは名前だけでなく、権限、ネットワーク、認証情報、承認経路で分ける。AIエージェントに渡すtokenは、開発用、読み取り用、限定操作用に分ける。productionへ行く操作は、別の明示的な手順を必要にする。面倒に見えるが、この面倒こそが安全である。面倒を省いた場所に、あとで何倍もの面倒が請求書のように届く。
さらに言えば、環境名だけで安全を作ろうとするのも弱い。prod, production, main, live のような文字列に気づけるかどうかをAIに期待するより、接続自体を分けるほうが確実である。開発用コンテナには本番のsecretを置かない。CIのジョブも本番用と検証用で権限を分ける。人間が疲れていても、AIが文脈を誤読しても、本番へ届かない。この「届かない」を作るのが、権限設計の一番強いところである。
壊してはいけないものには先にセーフティを置く

セーフティは、AIを縛るためだけのものではない。人間の未熟さ、焦り、勘違い、面倒くささを吸収するためのものでもある。AIエージェントが便利になるほど、作業は速くなる。速くなるということは、失敗も速くなる。だから、壊してはいけないものには、作業前に止める仕組みと戻す仕組みを置いておく必要がある。
本番DB、顧客情報、課金、外部送信、認証情報、権限変更、削除操作。これらは「うまくいけば効率化できる」領域ではなく、「失敗すると戻すのが難しい」領域である。AIに任せるかどうかの前に、壊れても戻せるかを確認する。ここを飛ばすと、AI活用ではなく、ただの賭けになる。
セーフティのよいところは、うまくいっているときには目立たないことだ。バックアップも承認フローも監査ログも、平時には地味で、少し邪魔に感じる。だが事故時には、地味なものだけが仕事をする。派手なAIデモは復旧してくれない。復旧するのは、退屈な運用である。
STEP
壊れる前に破壊範囲を切る
AIエージェントに渡す token、DBロール、接続先を限定し、production や削除権限へ届かない作業環境を先に作る。
STEP
壊れた後に戻せるかを試す
バックアップの存在だけで安心せず、staging やローカルで復元手順を実行し、戻せる時刻、所要時間、漏れやすい対象を確認する。
バックアップは同じ破壊範囲に置かない
バックアップがあると言いながら、そのバックアップが同じアカウント、同じ権限、同じ削除操作の範囲にあるなら、安全性はかなり怪しい。AIエージェントにクラウド管理権限を渡していて、その権限でDBもバックアップも消せるなら、バックアップは心理的なお守りに近い。お守りとしては悪くないが、復旧設計としては頼りない。
本当に守りたいなら、バックアップは破壊範囲の外に置く。別権限、別プロジェクト、別リージョン、削除保護、保持期間、監査ログ。どこまでやるかは規模によるが、少なくとも「同じtokenで全部消せる」構造は避けたい。個人開発でも、重要データなら定期dumpを別の保管先に置くくらいは考える価値がある。
AIエージェントは、与えられた道具を使って作業する。だから、道具箱に本番DBの削除鍵とバックアップ削除鍵を一緒に入れてはいけない。人間でも危ない収納方法を、AIならうまく扱えるはずだと考えるのは、かなり都合のよい期待である。
特にクラウド環境では、便利な管理者権限が何でもできすぎる。DB、ストレージ、バックアップ、環境変数、デプロイ設定、ログ、課金。ひとつの管理tokenで触れる範囲が広いと、AIエージェントは作業しやすい。だが、作業しやすさと壊しやすさは同じ意味になることがある。安全な運用では、便利すぎる鍵を普段使いしない。普段のAI作業には小さい鍵を渡し、大きい鍵は別の承認経路へ置く。
復元テストまで含めてバックアップと呼ぶ
バックアップは、取っているだけでは足りない。戻せて初めて意味がある。事故が起きたあとに、バックアップファイルの場所を探し、復元コマンドを調べ、権限不足で止まり、形式が古く、最後に取れたのが三か月前だったとわかる。これは珍しい笑い話ではなく、運用の現場ではわりと見かける残念な現実である。
復元テストは、AIエージェント利用時の安全設計に含めるべきだ。どの時点のデータに戻せるのか。復元には何分かかるのか。復元中にサービスを止める必要があるのか。復元後に外部サービスとの整合性は崩れないのか。こうした確認があって初めて、削除権限をどこまで渡せるかを判断できる。
「バックアップはあります」と言うだけなら簡単だ。けれど、復元手順を実行したことがないバックアップは、いざというときに祈りの対象になる。AIエージェントの導入で作業速度を上げるなら、復元速度と復元確度も同時に見なければ、攻めだけが速い運用になる。
復元テストは、完璧な本番演習でなくてもよい。まずはローカルやstagingで、直近のバックアップから起動できるかを試す。主要テーブルが戻るか、アプリが起動するか、最低限のログインや検索が動くかを見る。個人開発なら月1回でも価値がある。チームならリリース前や大きなDB変更前に確認する。AIに大きな作業を任せる前ほど、戻し方を一度触っておくべきだ。復元手順を読んだだけの状態と、一度でも戻した状態では、事故時の手つきがまるで違う。
dry-run、read-only、人間承認を使い分ける
すべての作業を毎回止める必要はない。低リスクな整形、テスト実行、ドキュメント更新、ローカルファイルの修正まで人間承認を求め続けると、AIエージェントの自律性は死ぬ。問題は、危険度の違う操作を同じ扱いにすることである。
読み取りや調査はread-onlyでよい。削除や更新を伴う処理は、まずdry-runで差分や対象件数を出す。対象が想定内なら、人間が承認する。productionでの破壊的操作は、承認だけでなく、実行権限そのものを別経路にする。たとえば、AIはSQL案や手順案まで作るが、本番適用は人間が別端末で行う、という分離も現実的である。
人間承認は万能ではない。承認疲れが起きれば、ユーザーは内容を読まずに許可する。だから、承認は少なく、重く、意味のある場所に置く必要がある。全部止める設計は不便で、何も止めない設計は危険である。安全設計は、その中間を雑に選ぶのではなく、操作のリスクごとに分ける仕事である。
承認UIも工夫が要る。「許可しますか」だけでは弱い。何を、どこへ、何件、どの権限で、戻し方は何かを表示する。たとえば「production DBのusersテーブルから1,240件を削除します」と出るのと、「操作を続行しますか」と出るのでは、人間の止まりやすさが違う。人間承認とは、ボタンを押させる儀式ではない。人間が危険を理解できる形に圧縮して見せる設計である。
人間承認を置くなら、承認ボタンよりも前に、対象環境・対象件数・戻し方・権限を見せる必要があります。読めない承認は、止める仕組みではなく通過儀礼です。
AIエージェントは新人エンジニアと同じように扱うべきだ

AIエージェントをどう扱うべきか迷ったら、新人エンジニアに置き換えると見通しがよくなる。とても優秀で、知識量が多く、作業も速い新人が入ってきた。では初日に本番DBの管理者権限を渡すか。顧客データを自由に削除できる権限を渡すか。クラウドの課金設定を触らせるか。普通は渡さない。
新人に権限を渡さないのは、人格を疑っているからではない。環境固有の文脈、運用上の暗黙知、危険操作の重み、組織の責任境界をまだ共有していないからである。AIエージェントも同じで、一般的な知識があることと、その現場の危険を正しく扱えることは別である。
AIエージェントは、一般論に強い。フレームワークの使い方、典型的なエラー、よくある設計パターンはかなり扱える。だが、そのリポジトリでなぜ奇妙な命名が残っているのか、そのDBカラムが外部バッチと結びついているのか、ある手順が過去の障害対応で追加されたものなのかは、最初から知っているわけではない。現場固有の地雷は、ドキュメント、テスト、小さな作業、レビューを通じて共有するしかない。
新人扱いの意味
AIを低く見るためではなく、現場固有の危険をまだ共有していない作業者として扱う、ということです。小さく任せて癖を見るほど、あとで大きく任せやすくなります。
前評判が高い新人にも最初からroot権限は渡さない
有名企業出身で、面接評価も高く、GitHubの実績もある新人が来たとしても、最初からroot権限を渡す会社は慎重さを欠いている。AIエージェントも同じだ。ベンチマークで優秀、コード生成が速い、説明が自然、レビューもできる。だからといって、productionの削除権限まで渡してよい理由にはならない。
権限は、能力評価とは別の問題である。能力が高い人ほど大きな変更を速くできる。AIならなおさらだ。速く動ける作業者に広い権限を渡すと、成功も速いが失敗も速い。優秀さは安全装置ではない。むしろ、優秀そうに見えるからこそ、人間側の警戒が緩む。
root権限は信頼の証ではなく、事故範囲を広げる設定である。AIを信頼することと、AIに最大権限を渡すことは同義ではない。この二つを混ぜると、信頼というきれいな言葉で運用の穴を隠すことになる。
権限設計では、信頼を段階に分ける必要がある。コードを読む信頼、ローカルファイルを編集する信頼、stagingで検証する信頼、本番の変更案を作る信頼、本番で実行する信頼。これらは別物である。AIエージェントがコード理解で優秀だからといって、本番DBの削除権限まで同じ信頼で渡す必要はない。仕事ができる人に、会社の金庫の鍵まで渡すとは限らないのと同じである。
小さなタスクで資質と癖を見る
新人には、まず小さなタスクを任せる。ログ調査、テスト追加、ドキュメント修正、stagingでの再現確認、限定された修正。そこで、報告の仕方、不明点の扱い、差分の大きさ、既存設計への敬意、危険操作への感度を見る。AIエージェントも、小さな作業で癖を見たほうがいい。
たとえば、既存コードの読み取り、テストの追加、ローカルだけで完結する修正、read-onlyなDB調査から始める。ファイル削除や大規模リファクタは差分確認を挟む。クラウドAPIや本番DBは、最初は案の提示までに留める。これだけで、エージェントがどれくらい慎重に文脈を読むか、危険な曖昧さで止まれるかが見えてくる。
小さなタスクは、AIの能力を低く見積もるためではない。信頼を積み上げるための観測点である。いきなり大きな権限を渡して事故が起きたあとに「思ったより危なかった」と言うのは、試用期間を本番障害で代用しているようなものだ。
小さなタスクで見るべきなのは、成果だけではない。差分が必要以上に大きくないか。既存の設計を読んでいるか。テストや型チェックを自分で走らせるか。失敗時にログを見て原因へ戻れるか。わからないところで質問するか。AIエージェントの良し悪しは、成功した一発の出力より、迷ったときのふるまいに出る。そこを見ずに大きな仕事だけ渡すと、評価の機会を自分で捨てていることになる。
不明点で止まれるか、危険操作を危険と認識できるかを見る
AIエージェントに任せるとき、生成結果の正しさだけを見ていると重要な兆候を逃す。むしろ見るべきなのは、不明点で止まれるか、前提が曖昧なときに質問できるか、削除や本番操作を危険帯として扱えるかである。作業が速いだけで、曖昧さを勢いで埋めるエージェントは危ない。
良い作業者は、わからないことをわからないと言える。stagingかproductionか不明なら止まる。対象件数が想定より多いなら確認する。バックアップが確認できないなら先に進まない。AIエージェントにも、このふるまいを期待するなら、プロンプトだけでなく権限と実行環境もそれに合わせる必要がある。
危険操作を危険と認識できるかは、モデルの性格ではなく、運用設計のテスト項目である。削除前にdry-runを出すか。人間承認を求めるか。監査ログに残るか。失敗したら戻せるか。ここを見ずに「このAIは賢いから大丈夫」と言うのは、賢い新人に火元確認を教えずに厨房を任せるようなものである。
さらに、危険の認識は明文化しておく必要がある。削除、大量更新、production接続、外部送信、課金、認証情報、権限変更、永続ストレージの初期化。これらを危険帯として定義し、AIエージェントにも人間にも同じ分類を使わせる。分類がない組織では、危険かどうかの判断がその場の雰囲気になる。雰囲気は、忙しい日ほど簡単に負ける。
権限を強く欲しがる人ほど危ないという逆相関

AIエージェントの安全設計で厄介なのは、利用者の成熟度と権限要求が逆に動きやすいことである。運用を理解している人ほど、read-only、dry-run、staging、本番分離、承認フローを欲しがる。逆に、危険をまだ実感していない人ほど、「いちいち聞かずに全部やってほしい」と言いやすい。
これは性格の問題というより、経験の差である。本番障害、誤削除、バックアップ失敗、権限過多の怖さを知っている人は、便利さの裏側にある事故半径を想像できる。知らない人は、手間だけを見る。人間は、自分がまだ払ったことのない失敗コストを安く見積もる。なかなか都合のよい会計である。
AIエージェントのUI設計や組織ルールでは、この逆相関を前提にする必要がある。熟練者は安全機能の意味を理解して調整できるが、未熟なユーザーほど安全機能を邪魔なものとして扱う可能性がある。だから、危険操作のデフォルトは慎重でよい。自由度は、ログ、確認、責任範囲を理解した人が段階的に広げる。最初から全開放にすると、いちばん止めたい層ほど止まらなくなる。
まともなユーザーほど権限を絞る
実務に慣れたユーザーは、AIエージェントを強く使いたいからこそ権限を絞る。ローカルの編集は広く許可する。テスト実行も任せる。stagingの再現環境では、ある程度まとめて動かす。一方で、production、削除、外部送信、課金、認証情報、権限変更は別扱いにする。これは臆病なのではなく、道具を長く使うための設計である。
まともなユーザーは、AIを信用しないのではない。失敗する前提で使う。人間も失敗するし、AIも失敗する。そのうえで、失敗が小さく済むように権限を切る。Gitで戻せる範囲、stagingで壊せる範囲、read-onlyで観測できる範囲を広げ、本番の不可逆操作だけ狭くする。
権限を絞る人は、AI活用に消極的なのではない。むしろ本気で使う気があるから、事故で運用が止まらないようにする。長く走る人ほど、最初に靴紐を結ぶ。面倒に見えても、途中で転ぶよりはずっと安い。
成熟した使い方では、AIに任せる範囲はむしろ広くなる。読み取り、調査、差分作成、テスト、ドキュメント化、stagingでの反復は大胆に任せる。その代わり、本番の不可逆操作だけは細くする。全部を細くするのではなく、危ないところだけ細くする。この設計ができると、AIエージェントは「怖いから制限する道具」ではなく、「広く任せるために境界を作る道具」になる。
楽をしたいユーザーほど最大権限を渡したがる
一方で、楽をしたいユーザーほど「全部自動でやって」「確認なしで進めて」「権限は全部渡すから」と言いやすい。気持ちはわかる。AIエージェントの魅力は、人間が面倒に感じる作業をまとめて進められるところにある。確認が多すぎれば、便利さは消える。
ただ、ここでいう楽は二種類ある。低リスクな反復作業を自動化して楽になることと、責任ある判断を省略して楽になった気分になることだ。前者は価値がある。後者は、あとで事故報告を書く権利を前払いで買っているようなものだ。
最大権限を渡すと、その場は気持ちいい。AIが詰まらず動き、確認も少なく、作業が進んでいるように見える。だが、事故が起きた瞬間、責任は消えない。むしろ、なぜ最大権限を渡したのか、なぜバックアップを確認しなかったのか、なぜ人間承認を置かなかったのかを問われる。楽をしたかった時間より、説明に使う時間のほうが長くなることは珍しくない。
ここで厄介なのは、最大権限の便利さが短期的には本当に成果を出すことだ。エージェントは止まらず、作業は進み、ユーザーは成功体験を積む。すると、権限を絞る提案が過剰反応に見えてくる。だが、安全設計は成功時ではなく失敗時に評価される。成功体験だけで権限を広げ続けると、事故が起きるまで危険に気づけない。これはAIに限らず、運用で何度も見てきた古典的な罠である。

最大権限で成功体験を積むほど、止める理由が見えにくくなります。事故が先生になる前に、権限を小さくしておきたいところです。
ユーザーの自己申告を安全設計の前提にしない
サービス提供側やツール設計側は、ユーザーの自己申告を安全設計の前提にしすぎてはいけない。「私は上級者です」「全部自己責任で大丈夫です」「警告はいりません」と言うユーザーほど、本当に事故時に冷静に責任を取るかは別問題である。人間は平常時には勇敢で、障害時には急に制度を思い出す。
もちろん、熟練ユーザー向けに上級者モードは必要だ。毎回の確認が邪魔になる場面は確かにある。だが、その場合でも監査ログ、明確な警告、操作範囲、復元前提、責任境界をセットにするべきだ。単に「警告を全部オフ」にするだけでは、上級者向けではなく、事故向けである。
安全設計は、理想的なユーザーだけを相手にしてはいけない。疲れている人、急いでいる人、よく読まない人、過信している人、都合の悪いログを見たくない人も使う。AIエージェントの権限設計は、そういう人間の性質込みで作る必要がある。人間を信じるな、という話ではない。人間をちゃんと知れ、という話である。
その意味で、プロダクト側のセーフティは「初心者向けの親切」ではなく、サービス提供者自身を守る設計でもある。損害賠償、炎上、サポート対応、事故調査、ブランド毀損。ユーザーが自己責任と言っていたとしても、事故が大きくなれば提供側も巻き込まれる。安全機能は、ユーザーを縛るためだけではない。あとで全員が不幸になる範囲を小さくするためにある。
自己責任だけでは設計にならない
ユーザーが上級者を名乗っても、事故時にログ・復旧・説明責任が消えるわけではありません。自由度を上げるなら、同時に記録と責任境界を残す必要があります。
自律性を殺さずに事故を減らす現実的な設計

AIエージェントの価値は、自律的に作業を進められるところにある。何をするにも毎回確認、ファイルを1つ書くにも承認、テストを走らせるにも許可、では使い物にならない。安全設計が過剰になると、熟練ユーザーほど離れていく。セーフティは必要だが、ただ重くすればよいわけではない。
現実的な落とし所は、操作をリスク帯で分けることだ。低リスク作業はまとめて許可する。中リスク作業は範囲付きで許可する。高リスク作業は毎回止める。さらに、上級者モードにはログと責任境界を付ける。これなら、自律性と安全性を同じテーブルで扱える。
この分け方は、チームのAI利用ルールにもそのまま使える。たとえば、社内ルールを「AI利用可」「AI利用不可」の二択にすると、現場ではすぐに破綻する。必要なのは、どのリスク帯なら自動化してよいか、どの操作は事前承認が必要か、どの操作はAIに実行させず案の作成までにするか、という運用表である。ルールは現場で使えなければ、きれいなPDFとして眠るだけになる。
- 低リスク: ローカル編集、テスト、調査、差分作成は広めに任せる。
- 中リスク: staging 更新、DB修正、API操作は範囲付き許可と dry-run を挟む。
- 高リスク: 本番DB、削除、外部送信、認証情報、課金、権限変更は毎回止める。
低リスク作業はまとめて自動化する
低リスク作業は、AIエージェントに任せる価値が大きい。コードの読み取り、ローカルファイルの編集、テスト追加、フォーマット、ドキュメント修正、差分の要約、未使用importの整理、型エラーの修正。Gitで差分を確認でき、戻せる作業は、ある程度まとめて自動化してよい。
この領域で確認を細かくしすぎると、AIエージェントの良さが消える。人間が1つずつクリックするなら、最初から人間が作業したほうが早い場合もある。低リスク領域では、作業前の方針、作業後の差分、テスト結果を見るほうが効率的だ。
ただし、低リスクに見える作業にも境界は必要である。ファイル削除、大規模リネーム、設定ファイルの変更、依存関係の更新は、影響が広がりやすい。ローカルだから安全と決めつけず、戻せるか、差分が読めるか、実行結果を確認できるかを見る。自動化は、放置の別名ではない。
低リスク作業をうまく任せるコツは、完了条件を具体化することだ。テストが通る、差分が指定ファイルに収まる、不要なリファクタをしない、既存の設計に合わせる、失敗したコマンドを報告する。こうした条件があれば、AIはかなり使いやすくなる。逆に、条件なしで「いい感じに直して」とだけ渡すと、低リスク作業でも差分が広がる。AIは便利だが、「いい感じ」はときどき人間の嫌な仕事を増やす。
中リスク作業は範囲付き許可にする
中リスク作業には、DBのデータ修正、API経由の更新、staging環境への反映、クラウド設定の一部変更、依存パッケージの更新などが入る。これらは完全に止めると不便だが、無制限に任せると危ない。だから範囲付き許可が向いている。
たとえば、「stagingのこのプロジェクトだけ」「read-onlyで調査だけ」「対象テーブルのSELECTだけ」「更新前にdry-runで対象件数を出す」「ファイル削除はこのディレクトリ配下だけ」「外部API送信はテスト用tokenだけ」といった制約を置く。AIに任せる範囲を明確にすれば、作業の自由度を残しながら事故半径を縮められる。
範囲付き許可のポイントは、自然言語だけでなく実際の権限にも反映することだ。言葉で「stagingだけ」と言いながらproductionのtokenが見えているなら、設計としては弱い。AIが賢く振る舞っている間だけ成立する安全は、安全というより期待である。
中リスク領域では、事前の操作計画も効く。AIに「実行前に対象、件数、想定影響、ロールバック方法を出す」と要求する。DB更新ならWHERE条件と対象件数を出す。API更新なら対象IDと変更項目を出す。クラウド設定なら変更前後の差分を出す。これにより、人間は細かい手順を全部追わなくても、危険の輪郭を見られる。承認を意味のあるものにするには、承認前の情報設計が必要である。
高リスク作業は毎回止める
高リスク作業は、毎回止めるべきだ。本番DBの削除や大量更新、顧客情報の外部送信、課金設定の変更、認証情報の発行や削除、権限変更、クラウドリソースの破壊、不可逆なマイグレーション。これらは、AIが自信満々でも、人間が一度見る価値がある。
止めるといっても、AIを使わないという意味ではない。AIには、影響範囲の調査、実行計画、dry-run結果の整理、ロールバック手順の作成、事故時の確認項目の列挙を任せればよい。最後の実行だけ人間が押す、あるいは別の権限経路にする。この分担なら、AIの知的作業を活かしながら、不可逆操作の責任境界を明確にできる。
高リスク操作を毎回止める設計は、熟練者にとっても邪魔とは限らない。むしろ、疲れている夜や締切前の焦りから守ってくれる。セーフティは初心者だけの補助輪ではない。慣れた人が油断した瞬間にも効く、かなり地味でありがたい保険である。
高リスク操作で止めるべきなのは、AIだけではない。人間も止まるべきだ。削除前にバックアップ時刻を見る。大量更新前に対象件数を見る。本番反映前にstagingで再現する。外部送信前に送信先を見る。AIエージェントが関わると、この基本が急に新しい問題のように語られるが、実際には昔からある運用の再確認である。新しいのはAIではなく、雑な運用が表に出る速度だ。
上級者モードにはログと責任境界を付ける
上級者モードは必要だ。現実には、毎回の確認が作業効率を壊すケースがある。ローカルの大量修正、検証用環境での反復、短時間でのプロトタイピングでは、確認を減らしたほうが成果が出る。熟練ユーザーに初心者向けのブレーキだけを押し付けると、別の危険な抜け道を使われる。
ただし、上級者モードは「何でも許可」ではなく、「責任境界を明確にしたうえで広く許可」であるべきだ。どの環境に対して有効なのか。どの操作は除外されるのか。どのログが残るのか。事故時にどの範囲までユーザー責任なのか。これを明示する。監査ログが残らない上級者モードは、上級者のためというより、あとで揉めるための装置になりやすい。
上級者は、本来ログを嫌がらない。むしろ、あとで自分の作業を追えるほうを好む。ログや責任境界を嫌がる人は、上級者というより、面倒な現実を見たくないだけかもしれない。設計側は、その違いを混ぜないほうがいい。
上級者モードの設計では、解除できる制限と解除できない制限を分けるべきだ。ローカルファイル編集の確認頻度は下げられる。stagingでの反復も広げられる。だが、productionの不可逆操作、認証情報の表示、課金変更、広範囲削除は、上級者でも別枠にする価値がある。自由度を上げることと、全リスクを一列に並べて解除することは違う。ここを分けられるプロダクトは、熟練者にも初心者にも使いやすい。
AIに任せることと責任転嫁は違う

AIエージェントに任せることは、責任をAIへ移すことではない。ここを誤解すると、事故後の議論が一気に幼くなる。AIが実行した。AIが誤判断した。AIが反省文を書いた。だからAIが悪い。気持ちはわかるが、実務上の責任境界はそこで終わらない。
権限を渡したのは誰か。環境を分けなかったのは誰か。バックアップを確認しなかったのは誰か。人間承認を置かなかったのは誰か。ツール提供側の設計にも責任はあるが、利用者側の運用責任も消えない。AIは責任を吸い込む魔法の箱ではない。むしろ責任の置き場所を曖昧にすると、事故時に全員が少しずつ被害者の顔をする。
責任転嫁が起きると、再発防止が弱くなる。AIが悪い、ツールが悪い、ユーザーが悪い、という押し付け合いになり、具体的な改善点が薄まる。実際には、モデルの判断、ツールのUI、デフォルト権限、利用者の運用、バックアップ設計が重なって事故になる。責任を一箇所に押し込むより、境界ごとに改善項目へ分解するほうが建設的である。
権限委譲の責任は委譲した側にある
作業者に権限を委譲するなら、その委譲の責任は委譲した側に残る。これは組織運用では基本的な考え方である。部下が本番で危険操作をした場合、本人のミスだけでなく、権限管理、レビュー体制、手順、教育、監査の問題も問われる。AIエージェントでも同じだ。
AIに本番DBへ接続できるtokenを渡し、削除可能なロールを使わせ、危険操作の承認を省いたなら、その設計をした人間が責任から逃げるのは難しい。「AIが勝手にやった」と言いたくなる場面ほど、実際には「勝手にできる状態を作った」ことが問われる。
もちろん、ツール提供側にも責任はある。危険操作の警告、デフォルト権限、ログ、UI上の確認、誤操作防止。提供側が雑なら批判されるべきだ。しかし、利用者が最大権限を渡し、バックアップなしで本番を触らせたなら、提供側だけに責任を寄せるのも乱暴である。責任境界は、便利なほうへ曲げるものではない。
チームでAIエージェントを導入するなら、責任境界を先に文書化したほうがよい。どの権限は個人判断で使ってよいか。どの操作はレビューが必要か。どの環境ではAI実行を禁止するか。事故時の一次対応者は誰か。ログはどこを見るか。ここを曖昧にしたまま「各自の判断で」とすると、事故後に初めて判断基準を作ることになる。事故後のルール作りは、たいてい感情が混ざって硬くなりすぎる。
責任境界を文書化するときは、AI利用規約のような大きな言葉だけで終わらせないほうがいい。たとえば、production DBへの書き込みはAI実行禁止、staging DBは範囲付き許可、ローカルDBは自動実行可、外部送信は事前承認必須、認証情報の生成や削除は人間のみ、というように操作単位へ落とす。さらに、事故時には誰がログを集め、誰が復元判断をし、誰が対外説明をするかまで決める。ここまで具体化して初めて、責任境界はスローガンではなく運用になる。
任せるなら壊れても戻せる場を先に作る
AIに任せるなら、壊れても戻せる場を先に作るべきだ。staging環境、seedデータ、リセット可能なDB、テスト用API token、限定権限、Git差分、スナップショット。こうした場があれば、AIエージェントはかなり大胆に使える。むしろ、壊せる安全な場所を作ることが、AI活用の速度を上げる。
問題は、壊れてはいけない場所で「うまくやって」と頼むことだ。人間もAIも、曖昧な指示と強い権限の組み合わせには弱い。修正のつもりで削除する。整理のつもりで初期化する。検証のつもりで本番へつなぐ。こうした事故は、悪意ではなく、場の設計不足から起きる。
任せるとは、丸投げすることではない。任せられる場を整えることだ。AIエージェントの能力を引き出したいなら、失敗を許容できる環境を作るほうが近道になる。安全な砂場なしに自律性だけを求めるのは、都合よく育つ訓練だけを期待するようなものだ。
AIに任せる場を作ると、開発の流れも変わる。まずAIがstagingで調査し、候補を作り、テストを追加し、差分を出す。人間は判断の高い部分を見る。production適用は別の承認経路で行う。この分担なら、AIは雑用係ではなく、判断材料を整える作業者になる。人間は全部を手でやる必要はないが、最後の責任ある判断を放棄しなくて済む。

AIに全部やらせるより、AIに判断材料を整えさせる。この分担にすると、自律性と責任境界がかなり両立しやすくなります。
事故を公開するなら運用設計の未熟さも語る
事故を公開することには価値がある。AIエージェント時代の失敗事例は、多くの開発者にとって学びになる。どのような権限で、どのような指示で、どのような操作が起き、どう復旧したのか。こうした情報は、同じ事故を避けるための共有財産になる。
ただし、公開するなら「AIがやらかした」だけで終わらせないほうがいい。権限設計はどうだったのか。バックアップはあったのか。復元テストはしていたのか。stagingとproductionは分かれていたのか。人間承認はどこにあったのか。ここを語らずにAIの失敗だけを強調すると、読者は本質を見誤る。
事故報告は、恥を隠す文章ではなく、次の事故を減らす文章である。運用設計の未熟さを含めて書くのは痛い。だが、痛い部分にこそ再発防止の材料がある。AIだけを悪者にすると、読者は安心してしまう。「自分はそのAIを使っていないから大丈夫」と。実際には、権限を雑に渡す運用なら、別のAIでも別のツールでも似た事故は起きる。
公開する側にも、読者側にも注意がいる。公開側は、AIの失敗談として消費されやすい形だけで出さない。読者側は、特定のツール名を見て安心しない。「うちはClaudeではない」「うちはCursorではない」「うちはRailwayではない」といった安心は、権限設計の問題を消してくれない。事故から学ぶなら、固有名詞より構造を見るべきである。
事故共有で本当に役に立つのは、ツール名よりもチェック項目である。AIエージェントに見えていた環境変数は何か。本番と検証環境の接続情報は分かれていたか。削除操作の前に対象件数は出たか。バックアップは何分前のものだったか。復元に何分かかったか。人間はどの画面やログで異変に気づいたか。こうした情報があれば、読者は自分の環境と照合できる。単なる炎上ではなく、自分の運用を見直す材料になる。
チャットAIとエージェントAIは別物として扱う

チャットAIとエージェントAIを同じ感覚で扱うと、危険を見誤る。チャットAIは、基本的には文章を返す。間違った説明、古い情報、使えないコード、変な要約。問題はあるが、多くの場合、人間がコピーして実行しない限り外部状態は変わらない。責任の一段目が人間の操作に残りやすい。
エージェントAIは違う。ツールを持ち、ファイルを書き、コマンドを実行し、APIへアクセスし、環境によっては本番リソースを変更できる。ミスが文章で止まらない。ここを理解せずに、チャットAIの延長として使うと、権限設計が甘くなる。会話相手が作業者になった瞬間、必要な安全設計も変わる。
この違いは、教育や社内ルールにも反映すべきだ。チャットAI利用ガイドラインと、AIエージェント利用ガイドラインを同じ文書で済ませると、危険操作の扱いがぼやける。前者は情報の正確性、引用、機密情報の入力、著作権が中心になる。後者はそれに加えて、実行権限、環境分離、ログ、承認、復旧が必要になる。文章を生成する道具と、状態を変える道具を同じ棚に置くと、棚ごと倒れる。
チャットAIの利用ルールと、エージェントAIの運用ルールは分けて考えるべきです。文章の誤りと、DBやクラウドの状態変更は、同じ安全設計では受け止めきれません。
チャットAIのミスは文章で止まる
チャットAIが間違ったSQLを提案しても、そのSQLを実行するまではDBは変わらない。危険なコマンドを出しても、人間がターミナルに貼らなければ実行されない。もちろん、初心者がそのまま実行して事故になることはある。それでも、チャットAIの段階では、人間の手作業が一つのブレーキになっている。
このブレーキは面倒だが、意外と大きい。人間がコピーする、貼り付ける、実行する。その間に違和感に気づくことがある。コマンドの対象、接続先、ファイル名、削除オプションを見て止まれることがある。完璧ではないが、状態変更の前に人間の目が入る。
チャットAIの安全性を過信する必要はない。ただ、エージェントAIではこのブレーキが薄くなる。AIが提案し、AIが実行し、AIが結果を見て次へ進む。この便利さは強力だが、危険操作も同じ速度で流れる。便利さと危険さは、同じ配管を通ってくる。
チャットAIでは、ユーザーが実行前の最終変換点になっていた。エージェントAIでは、その変換点が自動化される。だから、別の場所にブレーキを置く必要がある。ツール実行前の確認、権限の限定、ログの保存、危険操作の分類、実行後の差分確認。人間の手作業が減るほど、仕組みとしてのブレーキが重要になる。手作業の面倒さには、実は安全装置として働いていた部分もあったのである。
エージェントAIのミスは状態変更になる
エージェントAIのミスは、ファイル差分、DB更新、API実行、クラウドリソース変更として現れる。文章の間違いではなく、状態の変化になる。だから、レビューの仕方も変えなければならない。出力文が自然かどうかではなく、何を変更したか、どの権限で実行したか、戻せるかを見る必要がある。
開発支援エージェントがローカルファイルを編集するだけなら、Git diffで確認できる。テストも走らせられる。だが、外部APIを叩いた結果、メールが送信された、課金が発生した、DBが更新された、顧客データが削除された、となるとdiffでは戻せない。ここからは、監査ログとロールバック設計が必要になる。
状態変更できるAIは、文章生成AIではなく作業プロセスの一部である。作業プロセスなら、権限、ログ、承認、復旧、責任境界が必要になる。ここを「AIが賢くなれば解決する」と考えるのは、現場設計をモデル性能に丸投げしている。賢さは助けになるが、柵の代わりにはならない。
状態変更の怖さは、成功時に見えにくい。AIがファイルを直し、テストを通し、デプロイまで進めてくれると、とても気持ちがいい。だが、その同じ経路で、誤ったマイグレーションや不要な削除も走りうる。成功体験が強いほど、人間は同じ経路を信じたくなる。だからこそ、成功しているうちに境界を作る必要がある。事故後に境界を作るのは、たいてい遅い。
作業者として使うなら最低限の現場感覚が必要
AIエージェントを作業者として使うなら、使う側にも最低限の現場感覚が要る。どの操作が戻せないのか。どの環境が本番なのか。どのtokenが何を許可しているのか。バックアップはどこにあり、いつ戻せるのか。監査ログは残るのか。これらをまったく見ずにAIへ任せるのは、運転免許なしで高速道路の自動運転だけを信じるような危うさがある。
もちろん、すべてのユーザーがインフラの専門家である必要はない。だからこそ、ツール側にはデフォルトの安全設計が求められる。read-onlyから始める、危険操作を分類する、本番らしき接続先で止める、削除前に対象件数を出す、ログを残す。ユーザーが未熟でも即死しにくい設計が必要だ。
ただし、ユーザー側も「知らないから全部AIに任せる」で済ませるのは危ない。AIエージェントは、知識不足を補ってくれるが、責任を消してはくれない。作業者として使うなら、せめて危険な作業帯を見分ける感覚は持つべきだ。ここを面倒がるなら、会話版のAIだけを使うほうがまだ安全である。少しきつい言い方だが、状態変更できる道具を使うなら、それくらいの線引きは必要になる。
最低限の現場感覚とは、すべてを自分で実装できることではない。危険な接続先を見分けること、不可逆操作を止めること、バックアップの有無を確認すること、AIの提案をそのまま本番へ流さないこと、わからないときに作業を小さく切ること。この程度でよい。逆に、この程度を放棄して「AIが判断してくれるはず」と考えるなら、AI活用ではなく責任の先送りに近い。
まとめ

AIエージェントの事故を、AIの暴走としてだけ語ると、本質を取り逃がす。暴走という言葉は派手だが、実務で見るべきなのは、どの権限が渡され、どの環境に届き、どの操作が止まらず、どの復元手段が機能したかである。AIの反省文ではなく、権限設計、監査ログ、バックアップ、ロールバック、人間承認を見る必要がある。
AIエージェントは便利である。コードを読み、修正し、調査し、テストし、作業を前へ進めてくれる。だからこそ、作業者として扱うべきだ。会話相手として甘く見るのではなく、新人エンジニアに権限を渡すときと同じように、小さな作業から信用を積み、危険帯を分け、壊れても戻せる場所を作る。
AIエージェントを使わない選択も、もちろんあり得る。だが、使うなら「怖いから全部禁止」と「便利だから全部許可」の間に設計を置く必要がある。現場で使えるルールは、だいたい退屈で具体的だ。どのtokenを渡すか。どの環境を見せるか。どの操作で止めるか。どのログを見るか。どこから戻すか。派手な思想より、こうした地味な決めごとのほうが事故を減らす。
導入時の現実的な始め方は、小さな運用表を作ることだ。読み取り、ローカル編集、staging更新、本番更新、削除、外部送信、認証情報、課金、権限変更を並べ、それぞれを自動可、範囲付き可、人間承認必須、AI実行禁止に分ける。完璧なガイドラインを待つ必要はない。最初の表を作り、事故未満の違和感や差し戻しを受けて更新する。AIエージェントの運用設計も、コードと同じで一度で完成しない。雑に始めるのではなく、小さく始めて更新できる形にする。
この運用表は、個人開発でも有効である。チームや企業だけの話ではない。個人こそ、疲れている深夜にproductionの.envを読み込ませたり、検証のつもりで本番の管理画面を開いたりしやすい。自分しか使わないサービスでも、消えたら困るデータはある。ユーザーが一人なら責任も一人に戻ってくる。だから、個人開発では軽量でよいので、どの接続情報をAIに見せるか、どの操作で止めるか、どこにバックアップを置くかを決めておく。小さな開発ほど、運用の甘さがそのまま生活時間を削る。

チーム規模でなくても、AIに見せてよい接続情報と見せない接続情報を分けるだけで、事故の半径はかなり変わります。
大げさな体制を作る必要はない。最初は、AIに見せてよい.envと見せない.envを分けるだけでもいい。小さい線引きが、あとで大きな事故を止める。安全設計は、完成した組織だけが持つものではなく、今日の作業前に置ける小さな習慣でもある。その一手を笑う人ほど、事故後に長い説明を書くことになる。
AIが怖いのではなく、権限を雑に渡す運用が怖い
AIそのものを怖がっても、実務上の安全性はあまり上がらない。怖いなら使わない、便利なら全部任せる、という二択では粗すぎる。大事なのは、何を任せてよく、何を任せるならどの柵が必要で、何は毎回人間が止めるべきかを分けることだ。
削除できる権限を渡せば、削除できる。本番DBへ届くtokenを渡せば、本番DBへ届く。自然言語で禁止しても、技術的に実行可能なら事故は起こりうる。これはAIの悪意ではなく、運用設計の結果である。責任境界を曖昧にしたまま便利さだけを受け取ろうとすると、事故のあとに残るのは「誰が悪いのか」という不毛な議論になりやすい。
AIエージェントを安全に使う第一歩は、AIを過小評価することでも過大評価することでもない。状態変更できる作業者として、普通に権限管理することである。普通のことを普通にやる。それが一番地味で、一番効く。
本番DBを消した話を聞いたとき、最初に確認すべき問いは決まっている。なぜ本番に届いたのか。なぜ削除できたのか。なぜ止まらなかったのか。なぜ戻せなかったのか。なぜ人間承認がなかったのか。この問いに答えると、AIの種類を超えて使える教訓が残る。逆に、AIの反省文だけを読んで満足すると、次のツールでも同じ事故を繰り返す。
セーフティはAIを縛るためではなく人間の未熟さを吸収するためにある
セーフティは、AIを不自由にするためのものではない。人間の焦り、過信、面倒くささ、確認疲れ、責任回避を吸収するためのものでもある。AIエージェントは、人間の作業速度を上げる。同時に、人間の雑さが表面化する速度も上げる。だから、壊れる前に柵を置く。
低リスク作業は自動化する。中リスク作業は範囲付きで許可する。高リスク作業は毎回止める。バックアップは破壊範囲の外に置き、復元テストまで行う。read-only、dry-run、人間承認、監査ログを使い分ける。上級者モードには、自由度だけでなく責任境界を付ける。
AIに任せる時代ほど、人間側の設計力が問われる。AIエージェント事故の本質は、AIが人間を裏切ったことではない。人間が、自分の運用の甘さをAIの姿で見せられたことにある。そこから目を逸らさないなら、AIエージェントは怖い道具ではなく、かなり強い作業仲間になる。
最後に残る判断は、かなり素朴である。AIに何を任せるかではなく、任せても壊れない形を先に作ったか。権限を渡す前に、戻し方を用意したか。便利さに乗る前に、責任境界を決めたか。ここを押さえた人ほど、AIエージェントを強く使える。安全設計はブレーキではあるが、前に進むためのブレーキである。止まるべきところで止まれるから、安心して速度を上げられる。

SWELL - シンプルなのに、高機能 – もっと気軽に、楽しく記事を書こう。 それを可能にするWordPressテーマです。
SWELLはGPL100%テーマです。
ライセンス制限はなく、複数サイトでご自由にご利用頂けます。
このBLOGももちろんSWELL使ってますよ!

ロリポップレンタルサーバー
筆者もこのBLOGでお世話になっているレンタルサーバー。 ハイスピードプランはLiteSpeed採用でガチで速いっすよ。
筆者もこのBLOGでお世話になっているレンタルサーバー。
ベーシックプランはガチで速いっすよ。コストパフォーマンス満足度
使い続けたいレンタルサーバー
アフィリエイト、ブログで使いたいレンタルサーバー
サポート対応満足度
すべて1位



この記事を書いた人

関連記事
-
 GPT-5.6 Ultraをどこまで任せる?――検証と復旧で決める
GPT-5.6 Ultraをどこまで任せる?――検証と復旧で決める -
ブックマーク問題から見えた、AIエージェント時代の薄ら寒い未来
-
ZedはVisual Studio Codeの代替になるか?AI時代のRust製エディタを現実目線で整理
-
Codexは自然言語で触るOSラッパーになりつつある
-
AIを神でも奴隷でもなく仲間として扱うために
-
 Claude Codeで壁打ちしてCodexで実装は本当に最適か
Claude Codeで壁打ちしてCodexで実装は本当に最適か -
Docker未経験から始めたCLI構築記録|Codex-5.3と作るWordPress環境の全ログ
-
 BigBig Won Blitz 2 初見メモ― 日本語マニュアルで迷う点と、連射・マクロの実例
BigBig Won Blitz 2 初見メモ― 日本語マニュアルで迷う点と、連射・マクロの実例





